










0 of 0
About this mod
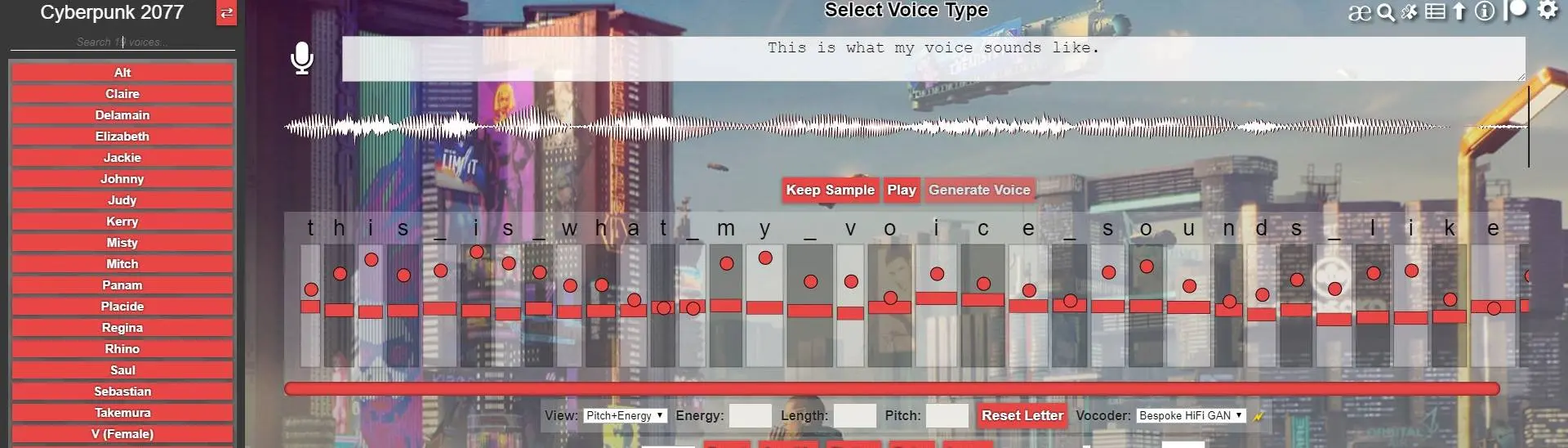
xVASynth is an AI tool for generating high-quality voice acting lines using voices from video games. The app supports hundreds of voices, across dozens of games, and provides pitch, duration, and energy control at per-letter granularity.
- Requirements
- Permissions and credits
- Changelogs
Download the main app from the Skyrim page. Main app now also on Steam!
You can now train your own voices: xVATrainer
List of voices available for xVASynth, from both myself and the community: Google doc link
You can submit models at the following link, if you train them with xVATrainer: Google forms link
Quick intro
xVASynth is an AI based app for creating new voice lines using neural speech synthesis. The app loads models individually trained on character voice data from games. The app gives users control over details such as pitch and durations of individual letters to provide control over emotion and emphasis. To see it in action, watch these short intro/tutorial videos, narrated by various supported voices:
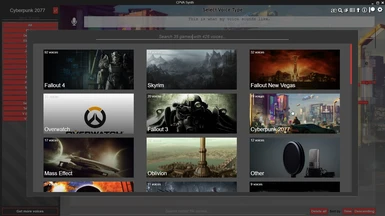
Supported games
Discord: https://discord.gg/nv7c6E2TzV
Patreon: https://www.patreon.com/xvasynth
Twitter: @dan_ruta
Preface: The tool does not re-distribute any game assets, nor does it interact with them in any way. Game assets are used only during voice training as a reference, to guide the algorithm to drive itself to a point where it can create voices that sound similar enough to the examples. Think about it as an automated digital impersonator. Regardless, avoid using the tool in an offensive/explicit manner. Make it obvious where you can, in descriptions that the voice samples are generated, and are not from real human voice actors. Any issues you cause with this are on you.
Introduction
xVASynth is an AI app that generates voice acting lines using specific voices from video games. It can do text-to-speech (TTS) from text input, or voice conversion (VC) from audio input (file/microphone). Starting with v3, the app gives users artistic control over pitch, duration, energy, emotion, and style values for every letter in the audio. They also allow generating audio with explicitly defined pronunciation via ARPAbet [3] notation. Every v3 model can speak any of the 28 supported languages, and can switch between multiple languages in the same text prompt.

The use of neural speech synthesis leads to natural sounding voices, something which is very difficult to do with more traditional methods involving concatenations of existing data. It also means new vocabulary can be generated, outside of what the voice actors have already read out.
Voice Conversion (v3+)
The app can also do voice conversion, rather than text-to-speech. In this mode, you can provide a reference audio dialogue file, and the app will re-generate it but with the voice of the v3 model you select. You can provide a reference audio line by recording with your microphone (by clicking the icon), or you can drag+drop an audio file onto the icon. If needed (unlikely), you can control the voice conversion strength in the settings.
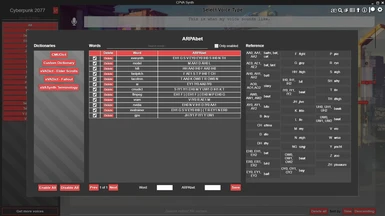
ARPAbet pronunciation (v2+)
You can specify exact pronunciation for words by using ARPAbet notation between { } brackets in the input, or by managing words in your own (or other people's) dictionaries. Included is CMUdict with 135k words with American-English pronunciations. NOTE: v3 introduces several new ARPAbet symbols, for a custom extended version of the ARPAbet spec which includes sounds more typically found in other languages.
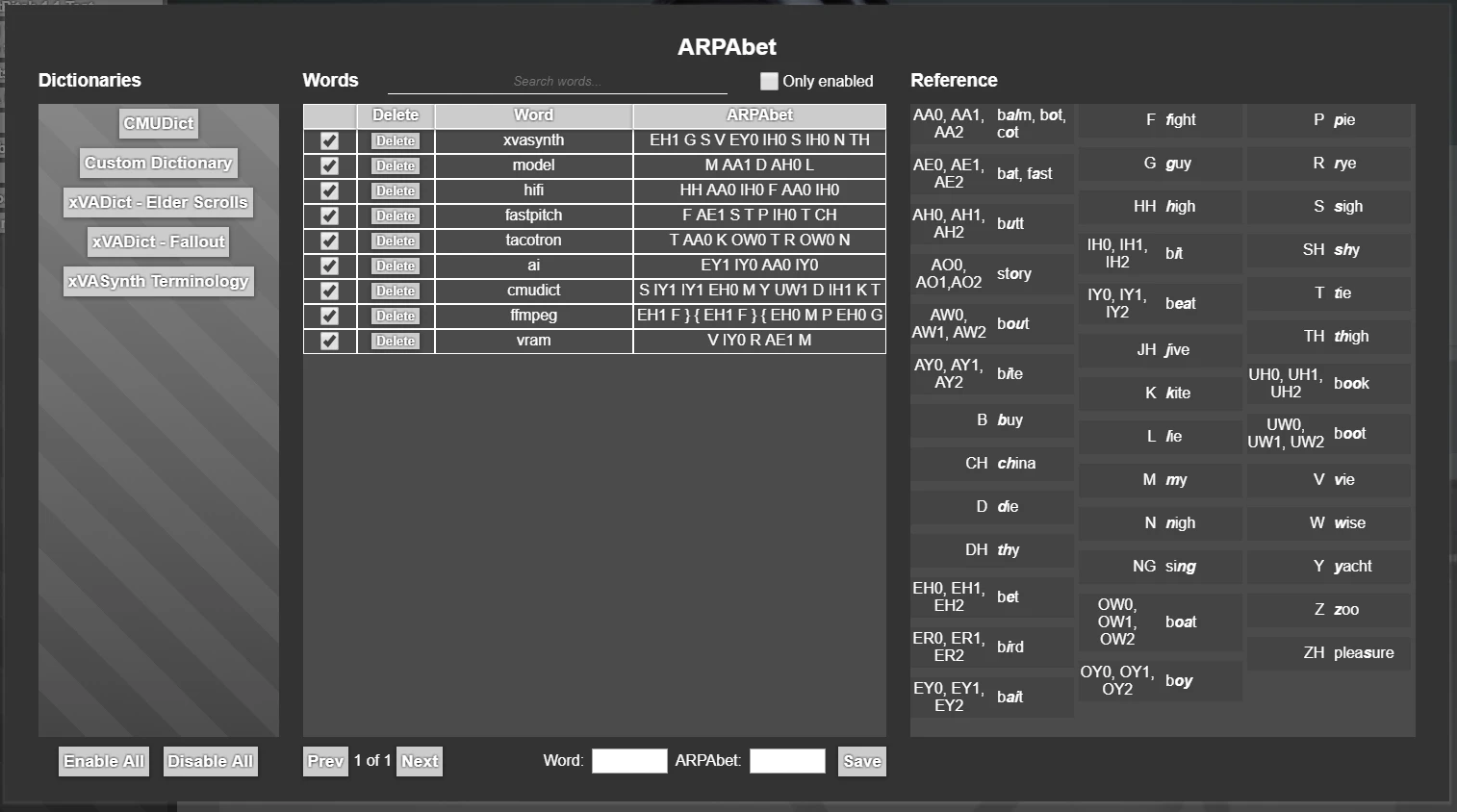
Other 3rd party dictionaries you can install into the app include:
xVADict community project - Elder Scrolls edition: https://www.nexusmods.com/skyrimspecialedition/mods/56778
xVADict is a community project to create ARPAbet pronunciation dictionaries, for use in xVASynth. This page contains the dictionary for the unique words found across all Elder Scrolls games.
xVADict - Alphabet Pronunciation: https://www.nexusmods.com/skyrimspecialedition/mods/57439
Adds the English alphabet pronunciation to xVASynth.
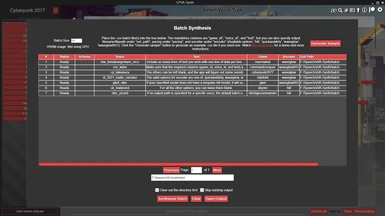
Batch Mode
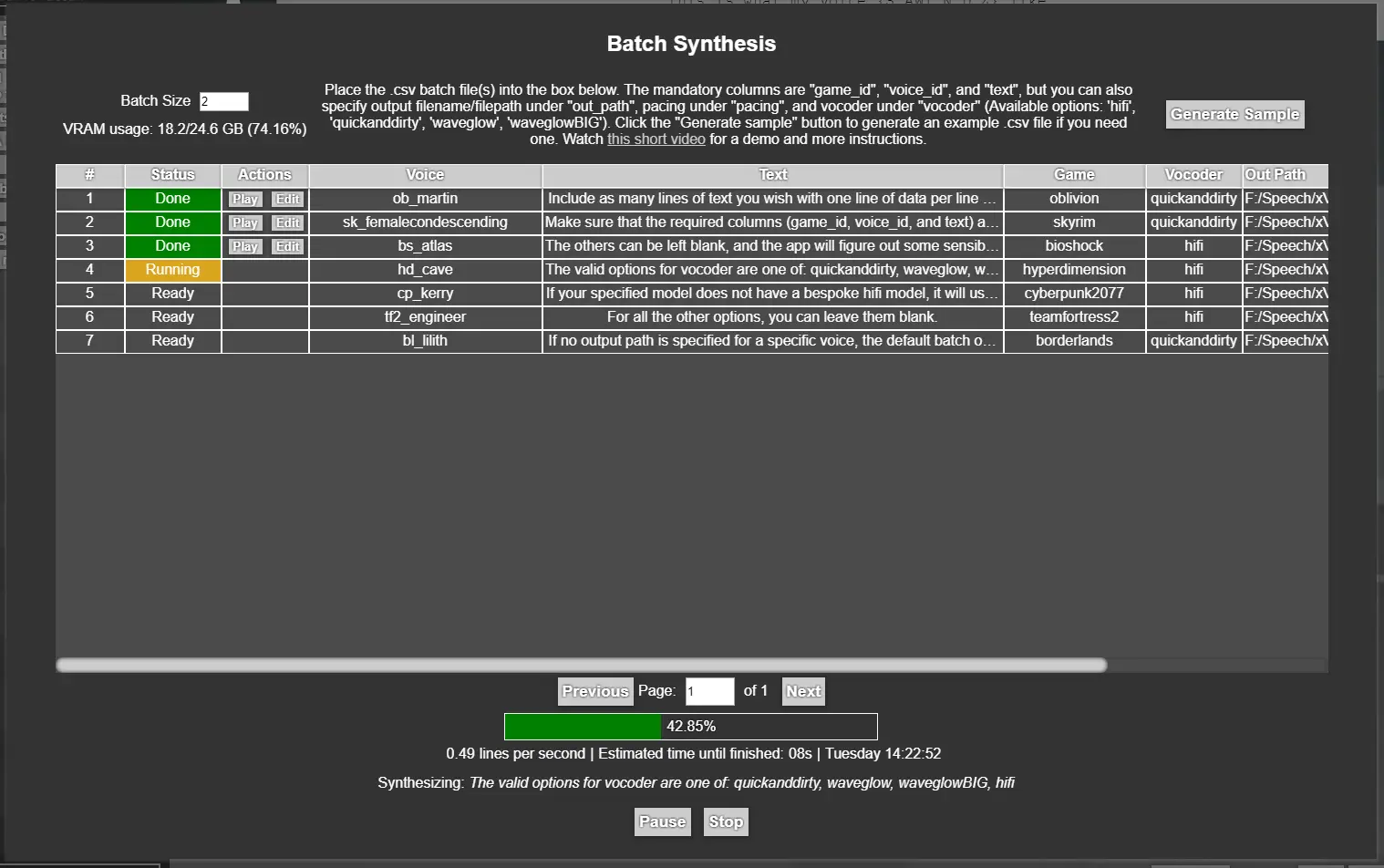
For larger projects, where you need to synthesize a large amount of lines, you can alternatively use the Batch synthesis mode. You can use either a .txt file or a .csv file to batch generate hundreds or even thousands of lines, in one go, with parallelization. Although the pitch/duration/energy editor is sometimes needed to get a line sounding just right, it's sometimes not needed, and this is a good way to get an initial pass on lines. Using the GPU is especially highly recommended for this, as you can greatly parallelize the number of lines generated in one go (limited by VRAM). You should also check the various settings, such as multi-threading, to get the best possible speed out of this for your system.
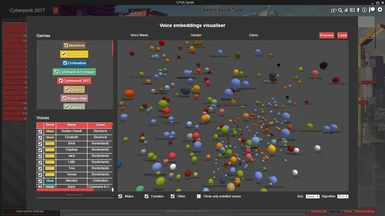
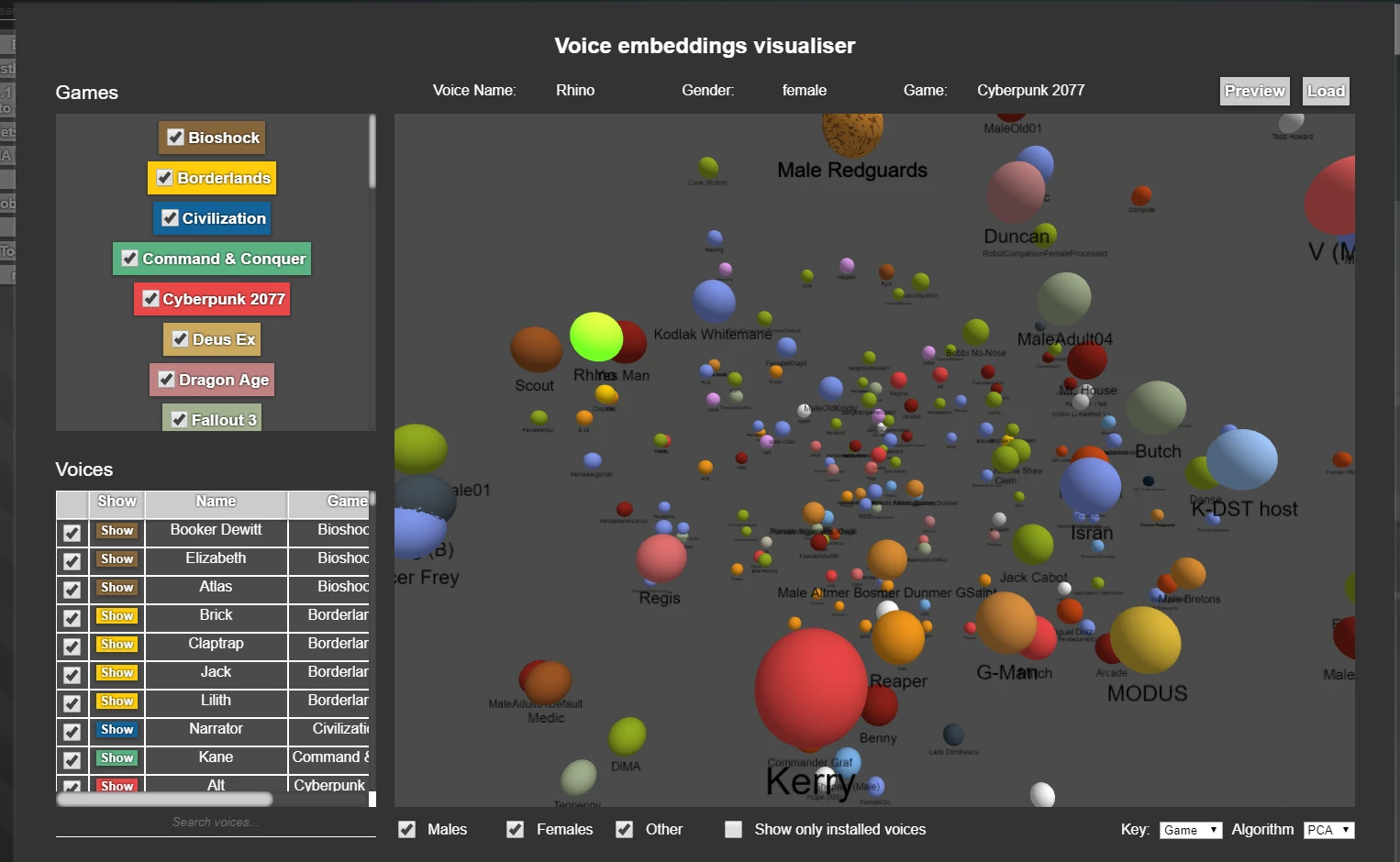
3D Voice embeddings visualizer
The 3D voice embeddings visualizer is an interactive panel where you can explore in 3D all the voices in the app, as seen by an AI representation learning model, projected down to 3D. There are no axes, and this serves purely as a visualization, to enable voice discovery. You can colour the points by game, or gender, and you can enable disable specific games/voices. You can load a voice by clicking it and the "Load" button, if it's installed.
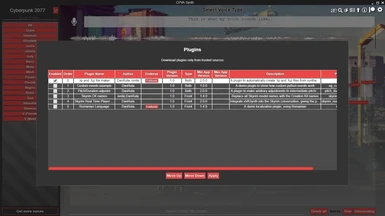
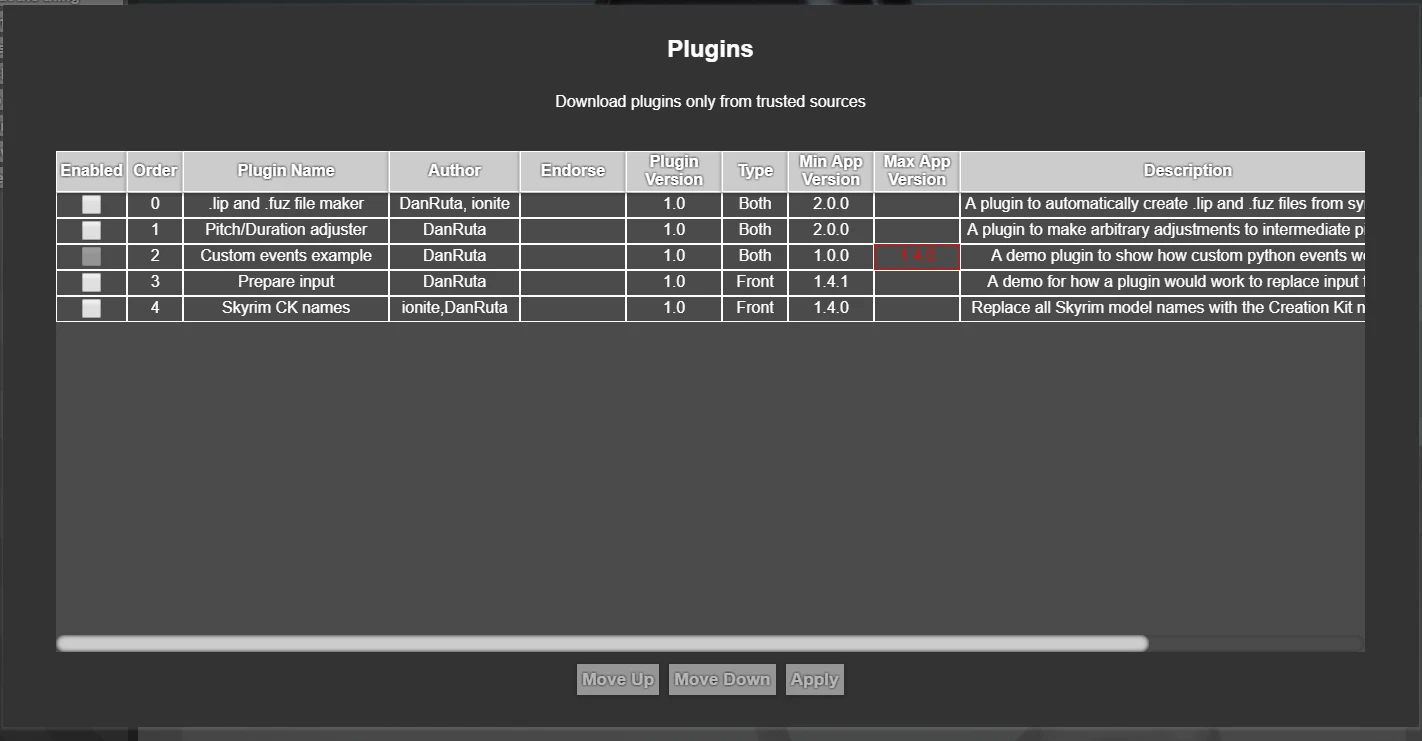
Third party plugins
The app supports third-party plugins for either/both javascript front-end (UI) and python back-end (AI) parts of the app. Plugins are a great way to customise the app to your liking, or to add new functionality to it that would be too niche or too game-specific to add to the base app for everyone. Plugins can be made for either/both the front-end/back-end of the app. Some example plugins are listed here (let me know if you make anything, and I will add it here):
Voiced Player - xVASynth Fuz Ro Bork plugin: https://www.nexusmods.com/skyrimspecialedition/mods/62944
A plugin to connect xVASynth up to Fuz Ro Bork, enabling xVASynth voices to be used in the Fuz Ro Bork mod.
.lip and .fuz plugin for xVASynth v2: https://www.nexusmods.com/skyrimspecialedition/mods/55605
A plugin to create .lip and (optionally) .fuz files automatically from audio lines generated with xVASynth, in either normal mode or batch mode, with or without multi-threading. DOES NOT NEED THE CK. Works for Skyrim, Fallout 4, Fallout 3, and Fallout New Vegas.
xVASynth plugin - Romanian Language: https://www.nexusmods.com/skyrimspecialedition/mods/50878
A demo plugin for v1.4.0+ of xVASynth, where third party plugins are now supported. This plugin changes the app front-end, swapping the UI language to Romanian. Full developer reference: https://github.com/DanRuta/xVA-Synth/wiki/Plugins
If you are a developer and are interested in developing a plugin, check out the documentation here: https://github.com/DanRuta/xVA-Synth/wiki/Plugins
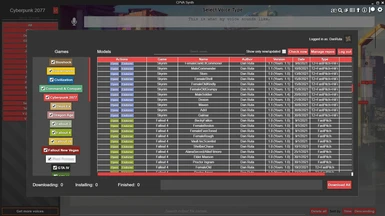
Nexus API integration
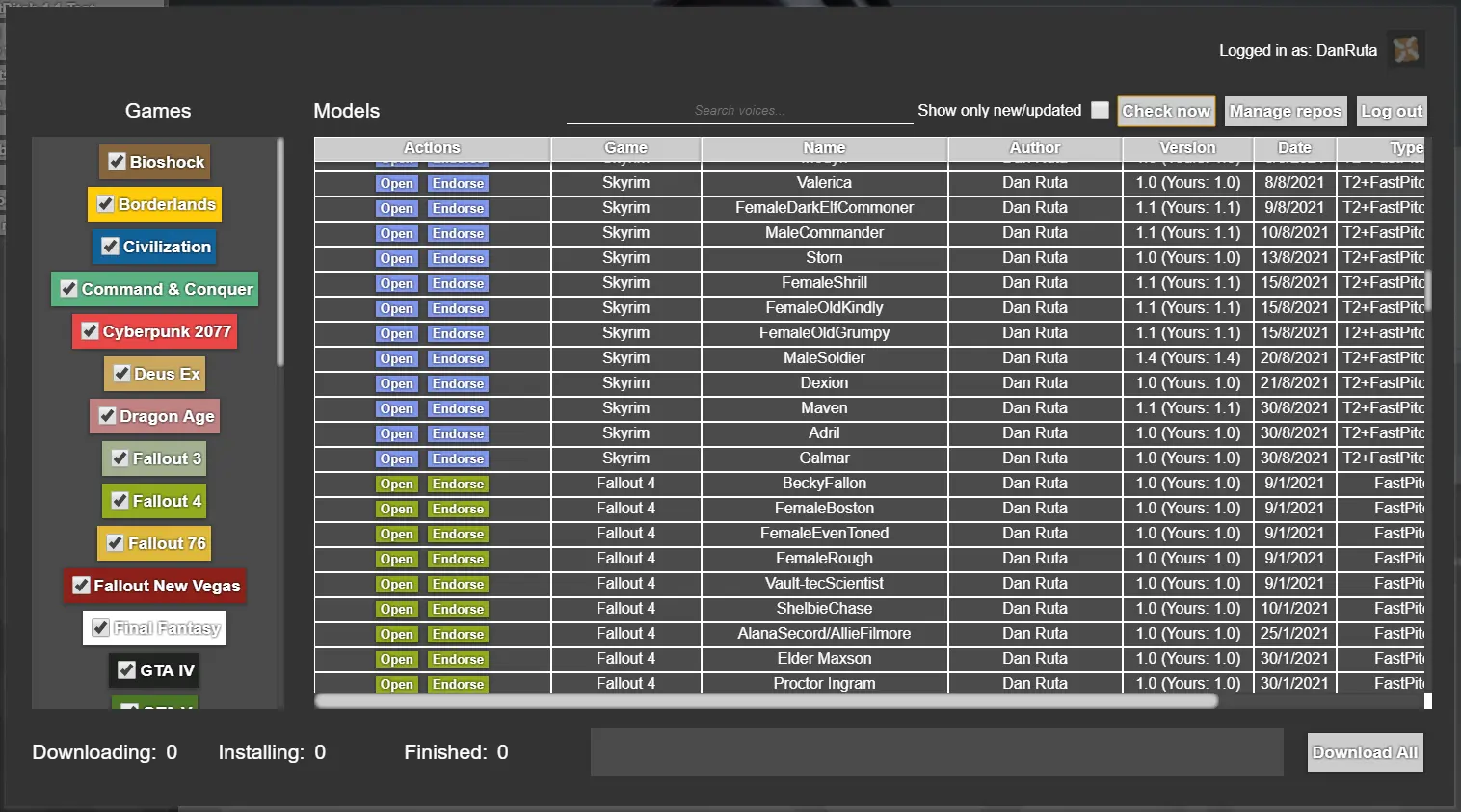
xVASynth has Nexusmods API integration to display what voices are available for updates/download, from any of the nexus pages listed in the "Manage Repos" sub-menu. If you have Nexus Premium, you can also download or batch download voices straight from within the app, and have them installed automatically.
App installation
You may need to install Microsoft Visual C++ Redistributable if you don't already have it. To install the app, download it and extract it anywhere you'd like (it does not need to be in any game directory). Launch the app by double-clicking the xVASynth.exe file. If you have any issues, try running it as admin, but be mindful that Electron on Windows has some issues with drag+drop events when running as Admin.
NOTE: v3 voices do not use a separate vocoder, as they are all-in-one models. You do not need/cannot use HiFi-GAN or WaveGlow models with v3 models
Important: Make sure you click "Allow" if windows asks you for permission to run the python server. I use a local HTTP server to enable communication between the python code (for the AI models) and the JavaScript code (for the Electron front-end). If there are any issues, check the server.log/app.log files (located next to xVASynth.exe) - there should be an error at the end which I'll need to see for helping with issues.
Voice installation
The recommended way to install voices is through the Nexus API integration. However, if you don't have Nexus Premium membership, or you'd prefer manual installation, you need to download the individual .zip files from the game-specific nexus pages (such as this one). You can either drag+drop these over the voice bar on the left in the app, or extract the voice files into the app directory, at this location: <.exe location>/resources/app/models/<game> where <game> is the game ID. The voice .zip files already contain the required directory structure, so all you need to do is drag+drop the extracted "resources" folder from the .zip files into the folder where the xVASynth.exe file is (replacing files if prompted).
To confirm, when installing voices, you should see 3 or 4 files (a .json, a .pt, a .hg.pt, and a .wav file) all named as the voice you're downloading, in <your xVASynth install directory>/resources/app/models/<game>/ (where <game> is cyberpunk, for models on this page).
Important: If you move the app files to a different directory, you MUST update the model paths in the settings, because these folder paths get initialized with the full path (starting from the drive letter) - basically, just make sure the app is looking in the new place where your models are, rather than the old folder. The app also allows you to set a different folder to store your voice models in, rather than nested in your app installation directory. The easier thing to do long-term would be to find somewhere not in your app installation folder to store your models, and set the app file paths to point there.
The voices
For Cyberpunk, the voices trained so far are as follows ("Track" the mod for updates):
v3 models:
Older:
Where green text colour represents good quality, yellow means ok quality, and red currently quite bad (will need a good deal of playing with the input to get something good). There are several types of models and variants of models supported by the app, so I will use emojis to try to clearly label what type of model each voice is:
? - This means the data for the voice is pre-trained using Tacotron2 [6], and the sentence structure/composition quality will be high
? - This means the voice comes with a bespoke HiFi [4] vocoder model, meaning the audio quality will be high
☢ - This means the voice model is FastPitch1.1, enabling energy control, speech-to-speech, and ARPAbet pronunciation. Tacotron2 isn't needed for this. (rad icon for RAD-TTS the built-in alignment mechanism replacing Tacotron2)
Note: To start with, most voice models will be v1.0 FastPitch, but they will eventually all be re-trained with the better v2.0 models with all the new features. I have over 425 voices to get through, so it may take a while.
You can optionally install WaveGlow [5] models from here, for extra vocoder options, but these are much slower, and almost always not as good as HiFi-GAN.
Tips
The most important thing to keep in mind is to make sure to play around with the editor, to get the best quality from the generated lines. If some words/letters sound bad, try changing the pitch/duration/energy values. Tinny artefacts can normally be fixed by slightly shortening the durations of offending letters. If you absolutely can't get it to say it well, and ARPAbet pronunciation doesn't help, try re-wording the line.
Check out the community guide here, where anyone can add their tips/advice for how to get the best quality out of the tool: https://github.com/DanRuta/xvasynth-community-guide You can also access this from the info (i) menu in the app.
Downstream uses
If you make anything with this tool (mod or otherwise), let me know and I will include it here.
YouTube playlist of xVA experiments (WaveGlow MaleSlyCynical): https://www.youtube.com/playlist?list=PLDGgH-fuVvfa8-HFdSi7ls1ykLIuquIpD
Radio New Vegas GPT-3: https://bunglepaws.neocities.org/radio_new_vegas_gpt3.html

[Fallout 4] Fallout 4 Point Lookout - Voiced Player Lines Addon: https://www.nexusmods.com/fallout4/mods/60387
XVASynth generated voice lines for Nate and Nora in the Fallout 4 Point Lookout mod.
[Fallout 4] Flashy(JoeR) - Gun For Hire - Commonwealth Mercenary Jobs: https://www.nexusmods.com/fallout4/mods/49610
Gun For Hire allows you to open a business outside of Diamond City and to run never-ending jobs for clients from a base of 27 different archetypes.
[Skyrim] Auto Sleep For Me Now: https://www.nexusmods.com/skyrimspecialedition/mods/56850
The most vanilla follower detect player auto sleep ever
[Skyrim] Sit For Me Now: https://www.nexusmods.com/skyrimspecialedition/mods/57423
Your follower auto sits with you
[Skyrim] Me So Hungry: https://www.nexusmods.com/skyrimspecialedition/mods/57184
NPCs cooking
[Fallout New Vegas] Easy Lanius: https://www.nexusmods.com/newvegas/mods/74565
Replaces Easy Pete's voice with a Lanius voice created by xVASynth2.
The Monster of the East has come to Goodsprings to retire.
[Skyrim] Teldryn Sero Dialogue Expansion: https://www.nexusmods.com/skyrimspecialedition/mods/42434
More unique dialogue for Teldryn Sero -- Adds conditional commentary and some player dialogue options.
[Oblivion] Oblivion Nouveau Uncut: https://www.nexusmods.com/oblivion/mods/47191
Adds over 50 npcs, 6 side quests & 1 questline, voiced Nord & Redguard guards, new locations & items, over 1000 lines of dialogue and much more!
[Oblivion] Chapter II - Daggerfall 3E433: https://www.nexusmods.com/oblivion/mods/49031
Welcome to the Kingdom of Daggerfall, Experience the entirety of Hammerfell & High Rock recreated lore friendly with Chapter II Content
[Fallout 4] Isran (Skyrim) Male Protagonist Voice Replacer: https://www.nexusmods.com/fallout4/mods/56972
Bored with the generic male protagonist voice? Don't like him saying sarcastic lines in an exaggerated way? Want to make a tough-looking character but the voice just doesn't cut it for you? This mod is for you! It replaces the male protagonist's voice with Isran's voice, making your character actually sound tough and threatening (and serious).
[Skyrim] The Courier Crew: https://www.nexusmods.com/skyrim/mods/110453
Adds two additional couriers w/ all courier voice lines for a total of three couriers
[Cyberpunk 2077] All Rhino All the Time: https://www.nexusmods.com/cyberpunk2077/mods/2826
Complete AUDIO AND VISUAL overhaul for various characters into the large muscular beauty, Rhino. Some have options for new skin, hair, and clothes, and some also have reworked female voices (via CPVA Synth).
[Skyrim] Phenderix Magic World: https://www.nexusmods.com/skyrimspecialedition/mods/6551
Phenderix Magic World adds a massive amount of content including new spells, weapons, bosses, followers, locations, and much more! Download today to unleash hundreds of new roleplaying options and discover a new world where magic has just begun to awaken.
[Skyrim] Wedding Outfit Commission: https://www.nexusmods.com/skyrimspecialedition/mods/52032/
Getting married? Commission wedding outfits for yourself and your spouse from Radiant Raiment! Now you and your betrothed can get hitched in style. (Fully voiced with brand new immersive dialog created using xVASynth)
[Skyrim] I'm Glad You're Here - a follower and spouse appreciation mod: https://www.nexusmods.com/skyrimspecialedition/mods/41856 (LE)
Allows the player to show their appreciation to their followers, spouse and adopted kids by dialogue and a hug animation. Voiced with vanilla assets.
[Skyrim] Less Generic Housecarls - Argis (Markarth) Dialogue Expansion and Quest: https://www.nexusmods.com/skyrimspecialedition/mods/48194/
Dialogue expansion and personal quest for Argis the Bulwark, your Markarth housecarl.
[Skyrim] Afterlife - Resurrected: https://www.nexusmods.com/skyrimspecialedition/mods/55051
Afterlife for NPCs is back! Valiant Nords will go to Sovngarde, while soul trapped characters will be sent to the Soul Cairn, upon death.
[Skyrim] VASynth Follower Dialogue Pack: https://www.nexusmods.com/skyrimspecialedition/mods/62488
This provides new voices to be used when creating follower NPCs.
[Fallout New Vegas] A World Of Speechless Pain - xVASynth NPC Voice: https://www.nexusmods.com/newvegas/mods/74992
A experimental mod which added voice for a few AWOP NPC, created by the tool which available for everyone.
[Skyrim] Voices of the Legendary Cities: https://www.nexusmods.com/skyrimspecialedition/mods/61634
Add voices generated with xVASynth 2 to all dialogues in the mod Legendary Cities - Tes Arena - Skyrim Frontier Fortress
[Skyrim] Maven Follower and Spouse Add-on: https://www.nexusmods.com/skyrimspecialedition/mods/61034
Turns Maven Black-Briar into a fully functional potential follower, spouse, "flower girl", and a much more likeable character overall. 350+ new fully voiced lines of dialogue, based on existing spliced audio and xVASynth-generated samples. Also turns Ingun into potential follower and spouse after you complete her quest.
[Skyrim] Blood on the Ice- Wuunferth Dialog Fix: https://www.nexusmods.com/skyrimspecialedition/mods/56378
Fixes a couple of inconsistencies with Wuunferth's dialogue during the quest 'Blood on the Ice'. ESL- flagged!
[Skyrim] Dovahsil - Alduin's Faction: https://www.nexusmods.com/skyrimspecialedition/mods/51231
This mod is designed to add another option to the end of the main quest: Siding with Alduin, burning down Sovngarde, and destroying the Blades.
[Skyrim] Dealing with Daedra: https://www.nexusmods.com/skyrimspecialedition/mods/40494 (LE)
Warlock style magic systems and new factions. Magic systems offer power for a price to non-mage characters. New factions provide "quests" and gameplay hubs. Aimed at creating new character build opportunities.
[Fallout 4] Nuka-World Reborn: https://www.nexusmods.com/fallout4/mods/32857?
Nuka-World Reborn is a quest mod which not only allows you to have multiple options to get rid of the raiders, but it adds new questlines to Nuka-World and allows you to play as a Trader.
[Fallout 4] Viva Nuka-World: https://www.nexusmods.com/fallout4/mods/37356
The sequel to Nuka-World Reborn - Viva Nuka-World is set after the events of Nuka-World Reborn, offering a more rigid quest design, more detailed dialogue scenes, configuration options and more...
[Skyrim] Positive Undressed Reactions: https://www.nexusmods.com/skyrimspecialedition/mods/44334
New lore-friendly voiced reactions to the player being undressed, using xVASynth, unused lines and splicing.
[Skyrim] Daejanggeum: https://www.nexusmods.com/skyrimspecialedition/mods/52518/
1. ESL, Fully voiced perfect healer, main quest helper. 2. There are story quests. and light scripts(never heavy). 3. Lite mod with only heals, no voice, no script at all.
[Skyrim] The Windhelm Smelterworks: https://www.nexusmods.com/skyrimspecialedition/mods/46333
The Windhelm Smelterworks adds an industrial scale smelterworks outside Windhelm, bringing some depth and immersiveness to Skyrim’s heavily mining dependent economy
[Skyrim] Cait in Skyrim: https://www.nexusmods.com/skyrimspecialedition/mods/44982
Bring Cait from Fallout 4 to Skyrim. Fully voiced using Cait's voice! Currently has 79 voiced lines. I've recreated a number of the original lines from Fallout, some "tweaked" ;) and a LOT of new lines!
[Skyrim] The Elder Scrolls Legends Imports: https://www.nexusmods.com/skyrimspecialedition/mods/32104
Adds references to Elder Scrolls: Legends cards and story into the world of Skyrim.
[Oblivion] NewCity_SI_Passwall_ENG: https://www.nexusmods.com/oblivion/mods/50837
Here you have the Russian mod NewCity Passwall, fully translated into English
[Skyrim] Ysolda Roasts Jon: https://www.nexusmods.com/skyrimspecialedition/mods/44630
Recreates the famous "Lamar Roasts Franklin" scene with a skyrim flavor using Ysolda and Jon Battle Born
[Skyrim] Dyudyaev-Kun: https://www.nexusmods.com/skyrimspecialedition/mods/44753
Adds a Male Woodelf dragonborn to your game.
He is a custom voice follower based on the Male young eager voice. ( use SKVA Synth)
[Skyrim] Nether's Frea: https://www.nexusmods.com/skyrimspecialedition/mods/49018
A complete overhaul to Frea including new voiced dialogue, quest and location awareness, dynamic lines from player actions, npc interaction, combat enhancements, new abilities, non-combat bonuses, customized skin, sculpted face and more! A Frea overhaul like you've never seen before.
[Skyrim] Nether's Karliah: https://www.nexusmods.com/skyrimspecialedition/mods/49334
A complete overhaul to Karliah including new voiced dialogue, quest and location awareness, dynamic lines from player actions, npc interaction, combat enhancements, new abilities, non-combat bonuses, customized skin, sculpted face and more! A Karliah overhaul like you've never seen before.
[Skyrim] Nether's Eola: https://www.nexusmods.com/skyrimspecialedition/mods/57250
A wickedly macabre, darkly humorous re-imagination of Skyrim's Eola. Features an enhanced, tweaked follower with plenty of options, an additional follower by the way of Nimphaneth (wood elf cannibal necromancer), extensive idle interactions between Eola and Nimph (if you use them both), harvesting of "tasty meat" from humanoids and MUCH MORE!
[Skyrim] Bards Reborn Student of Song Become a Bard Expansion with Bard Spells:https://www.nexusmods.com/skyrimspecialedition/mods/47994
This mod give the Bards College a massive makeover, adds a new study quest, new bardic spells, and a new character to flesh out your experience as a Bard. It includes all the great features of Become a Bard and expands on their use in the game.
[Skyrim] Authentic Sinding Follower SE: https://www.nexusmods.com/skyrimspecialedition/mods/33517
Gives Sinding a whole visual makeover and makes him a potential follower if you decided to help him during the Daedric quest "Ill Met by Moonlight".
[Skyrim] Susena Steel-Wolf Follower: https://www.nexusmods.com/skyrimspecialedition/mods/49493
Add Susena Steel-Wolf to Skyrim. She is staying at the Silver-Blood Inn in Markarth. She is the toughest mercenary in Skyrim. She has additional voices using SKVA Synth - xVASynth and has as much dialogue as Teldryn Sero. Her voice type is FemaleYoungEager.
[Skyrim] Random Guard Dialogues: https://www.nexusmods.com/skyrimspecialedition/mods/44378
New funny and random voiced dialogues for guards made with xVA-Synth
[Skyrim] Nazeem as a Follower: https://www.nexusmods.com/skyrim/mods/107792/
Nazeem as a follower, but with the assistance of XVASynth to give him voiced dialogue.
[Morrowind] Voicelines for Nord Fighters Guild Males: https://www.nexusmods.com/morrowind/mods/50105
Voicelines for Nord males of the Fighters Guild. They will address you as Journeyman to Master with different lines depending on your disposition.
[Skyrim] Stop right there criminal scum: https://www.nexusmods.com/skyrimspecialedition/mods/44181
A mod to add the infamous Oblivion line to Skyrim guards
[Skyrim] Female Hirelings: https://www.nexusmods.com/skyrimspecialedition/mods/48795
There is only one female Hireling in Skyrim. This makes *all* of them female (just Belrand atm). Fully voiced with natural looking faces.
[Skyrim] Trigger King Olaf's Festival Any Day - With Proper Ending SE: https://www.nexusmods.com/skyrimspecialedition/mods/46766
With this mod you can tell Viarmo to spontaneously arrange a festival on the same night. Also makes sure that each festival will automatically end at 4AM
[Skyrim] Your Choices Matter - A Dark Brotherhood Expansion: https://www.nexusmods.com/skyrimspecialedition/mods/46871 (LE)
This mod extends the Dark Brotherhood questline in many ways and adds an optional alternate ending. The ending you get will depend on the choices you, the Player make, throughout the story. Completely voiced dialogues, using vanilla and xVASynth assets.
[Skyrim] Adoption without Murder (Innocence Lost for Good Guys): https://www.nexusmods.com/skyrimspecialedition/mods/46741
A tongue-in-cheek alternative solution for Innocence Lost, for when you maybe want to adopt an orphan but without all that murder and stuff.
[Skyrim] Female Hirelings: https://www.nexusmods.com/skyrimspecialedition/mods/48795
There is only one female Hireling in Skyrim. This makes *all* of them female (just Belrand atm). Fully voiced with natural looking faces.
[Skyrim] M'aiq The Liar Anniversary Edition (aka Modder's Edition): https://www.nexusmods.com/skyrimspecialedition/mods/58958
Adds additional quirky not-quite-but-almost-fourth-wall-breaking dialogue lines to M'aiq the Liar celebrating 10 years of modding Skyrim.
[Skyrim] Thogra gra-Mugur - Orc Follower and Quest: https://www.nexusmods.com/skyrimspecialedition/mods/58979
Help an Orc widow get revenge on the one who wronged her. Multiple body options, custom dialogues, a quest with different endings, and more! Compatible with SE and AE.
[Skyrim] Fjotra Sybil of Dibella as a Young Adult: https://www.nexusmods.com/skyrimspecialedition/mods/56877
The new Sybil of Dibella is now a young adult, fully voiced and with a new quest.
[The Witcher 3] New Quest - Strange things: https://www.nexusmods.com/witcher3/mods/6156
New story about Ciri from another world.
Created using Radish Modding Tools.
P.S. My amateur quest.
[Skyrim] Serana Relationship Revamped: https://www.nexusmods.com/skyrimspecialedition/mods/59341
A mod that aims to enhance Serana as a character and her relationship with the player character. The intent is to stay as faithful to Bethesda's original rendition while exploring new avenues of conversation and a gradually evolving relationship, either platonic or romantic which is based on how the player character interacts with her.
[Skyrim] Flashy(JoeR) - Lydia Redefined - An Advanced Follower System: https://www.nexusmods.com/skyrimspecialedition/mods/62795
Lydia: Redefined provides a parallel follower system to significantly enhance adventuring with (nearly) everyone's favorite housecarl.
[Mass Effect] Nobody Cheated: https://www.nexusmods.com/masseffectlegendaryedition/mods/1032
This is the Legendary Edition version of the existing mod, Nobody Cheated. This mod allows a Female Shepard that had a romance in LE2 to respond to Kaidan when he accuses her of cheating.
[Fallout 4] Karliah (Skyrim) Female Protagonist Voice Replacer (British Accent): https://www.nexusmods.com/fallout4/mods/58235
Replaces the female protagonist's voice with the voice of Karliah from Skyrim. Karliah's voice is unique and she speaks in a British accent in Skyrim. Give your new character a new personality with this voice replacer mod!
[Fallout 4] Talk Like Arnie - Terminator Parody Mod: https://www.nexusmods.com/fallout4/mods/59275
This mod will replace the voice of the main protagonist with a new voice that closely resembles that of a Terminator Arnold Schwarzenegger. Many dialog lines in the game are also replaced with one-liners and memes like "Get to the choppa!" or "Hasta la vista, baby!" For female protagonists, your voice now resembles TSSC's Cameron (Summer Glau).
[Fallout 4] Nuka World Plus: https://www.nexusmods.com/fallout4/mods/31164
One of the main concerns from players of the "Nuka-World" DLC was
that as a good Player, there isn't much to do in Nuka-World after completing the quest, "open season". I
want to change that!
[Skyrim] Philmorex - A Rideable Steerable Dragon Follower: https://www.nexusmods.com/skyrimspecialedition/mods/63338
Philmorex is a rideable, steerable dragon follower. He will accompany you in your travels, and will assist you in your battles - aside you, or while you are riding him. Use intuititve commands to fully control your flight. Call for him again at any time after you have asked him to wait or leave, and Philmorex will return to you.
[Skyrim] Cutting Room Floor - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66278
Add new greeting dialogues for some NPCs from Cutting Room Floor using xVASynth2.
[Skyrim] Glenmoril and Unslaad xVASynth Voiced: https://www.nexusmods.com/skyrimspecialedition/mods/65959
used xVASynth 2 to generate voiced lines for Glenmoril and Unslaad
[Fallout 4] Cait (Fallout 4) Female Protagonist Voice Replacer (Irish-ish accent): https://www.nexusmods.com/fallout4/mods/59308
Replaces the player's voice with Cait's voice from Fallout 4. Live as an Irish lass in the Commonwealth!
[Fallout 4] Carl Johnson (CJ) in Fallout 4 - Voice replacer and face preset: https://www.nexusmods.com/fallout4/mods/60119
This mod brings Carl Johnson (CJ) from GTA San Andreas as a playable character in Fallout 4. The voice is replaced via xVASynth, and the face preset can be loaded via Looksmenu.
[Skyrim] Say my name: https://www.nexusmods.com/skyrimspecialedition/mods/56774
Say my name changes game lines to make NPCs actually speak out (audio) your character's custom name, instead of referring to you as "Dragonborn". Audio generated via xVASynth.
[Skyrim] Oakwood - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66971
Added new greeting lines for NPCs from Oakwood mod, voices generated by xVASynth2.
[Skyrim] Fishing - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67053
Improved the narrative of Fishing questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] M.E.I. - Maven Elenwen Ingun - Followers and Spouses Add-on: https://www.nexusmods.com/skyrimspecialedition/mods/61034
Turns Maven, Elenwen and Ingun into fully functional potential followers, spouses, and a much more likeable characters overall. 750+ new fully voiced lines of dialogue, based on existing spliced audio and xVASynth-generated samples.
[Skyrim] iNeedy: https://www.nexusmods.com/skyrimspecialedition/mods/67475
a Vocal compliment to Isoku's iNeed
[Skyrim] Redguard Elite Armaments - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67532
Improved the narrative of Interception quest from Redguard Elite Armaments with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] The Gray Cowl Returns - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67439
Improved the narrative of The Gray Cowl Returns quest with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Ghosts of the Tribunal - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67374
Improved the narrative of Ghosts of the Tribunal questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Saints and Seducers - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67117
Improved the narrative of Saints & Seducers questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Shor's Stone - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66454
Add new greeting dialogues for NPCs added by Shor's Stone mod using xVASynth2.
[Skyrim] Darkwater Crossing - Voiced Meieran: https://www.nexusmods.com/skyrimspecialedition/mods/66393
Add new greeting dialogues for Meieran from Darkwater Crossing mod using xVASynth2.
[Skyrim] Companion Yngvarr SE: https://www.nexusmods.com/skyrimspecialedition/mods/32048
An old Nord warrior longing for Sovngarde, cursed by beast blood.
Custom voiced using and editing Kodlak Whitemanes voice, unused dialogue and xVASynth. SE port.
[Skyrim] Mistborn - An Immersive Follower Collection: https://www.nexusmods.com/skyrimspecialedition/mods/67896
An immersive follower collection with intro quests, custom dialogue, and additional follower features, such as training and spell teaching.
(This is NOT based on Brandon Sanderson's "Mistborn" series.)
[Skyrim] EVG Animated Traversal: https://www.nexusmods.com/skyrimspecialedition/mods/63232
A framework to add new animation prompts for the player to climb ledges, squeeze in tight spaces, jump over walls and more.
[Skyrim] Jed The Guard Voiced NPC: https://www.nexusmods.com/skyrimspecialedition/mods/69627
Jed is a lazy, grumpy guard who is jaded by decades of guard duty and comes with a custom voice created with xVASynth. Contains some adult dialogue and humour which some may find offensive. ESL flagged.
[Fallout 4] Keanu Reeve's Voice Replacer for Male Protagonist: https://www.nexusmods.com/fallout4/mods/61252
Replaces Fallout 4's male protagonist's voice with Keanu Reeve's voice using the model of Johnny Silverhand from Cyberpunk 2077. Now you can finally play a John Wick playthrough!
[Skyrim] Guards Found Your Sweet Roll: https://www.nexusmods.com/skyrimspecialedition/mods/71697/
Guards will occasionally give you a sweet roll. A random chance, will happen only if you don't already have one in your inventory.
Fully voiced with spliced and xVA-generated lines. ESP-FE.
[Skyrim] Remiel-Custom Voiced Dwemer Specialist and Companion: https://www.nexusmods.com/skyrimspecialedition/mods/51874
Adds Remiel to your game, custom voiced with ~2500 lines of dialogue, a Breton engineer who will accompany you in your travels. She's travelled from Wayrest to explore dwemer ruins in Skyrim, but she needs your help. While she's not much of a fighter, she boasts a knack for machinery and will reprogram a dwemer spider to fight alongside you both.
[Skyrim] Breakable Equipment System: https://www.nexusmods.com/skyrimspecialedition/mods/23686
Another equipment break/degradation mod. Compatible with ALL well-made weapon/armor mods. Compatible with ALL armor slots. Compatible with PC and NPCs. Broken equipment can be repaired at grindstone or workbench. Equipment in NPCs' inventory, equipment in containers and eqiupment placed at habitable area are randomly temper
[Skyrim] Love and Expectations - The Story of Olfina Gray-Mane and Jon Battle-Born (Voiced with xVASynth): https://www.nexusmods.com/skyrimspecialedition/mods/72003
Love and Expectations adds a new questline focusing on Olfina Gray-Mane and Jon Battle-Born with a greater focus on player choice and outcomes. Will you help Olfina and Jon keep their secret? Or will you tell their families? Contains 1 quest with 2 optional following quest.
[Oblivion] Companion Arren - voiced: https://www.nexusmods.com/oblivion/mods/52203
The companion mod Arren by Sein_Schatten has over 3000 lines of dialogue, but sadly lacked voice, although silent voice files were present for all conversations. Here are all voice files.
[Skyrim] Lakvan's Stronghold - Shadowkey Dungeon and Player Home: https://www.nexusmods.com/skyrimspecialedition/mods/71084
Battle your way through Lakvan's Stronghold and claim it as your own. Fully voiced dungeon experience with references to TES Travels: Shadowkey.
[Oblivion] Mods Aware M'aiq (MAM) and fish stick dialogue fix: https://www.nexusmods.com/oblivion/mods/52418/
This mod makes M'aiq the Liar aware of your installed mods and adds up to 109 new VOICED dialogues to M'aiq the Liar, depending on the mods you have installed. Some vanilla dialogues can be also removed depending on your mods. It also fixes vanilla dialogue about fish sticks.
[Skyrim] Katria: https://www.nexusmods.com/skyrimspecialedition/mods/59966
This mod is a complete overhaul for the vanilla Katria. Her vanilla voice has been completely replaced. Includes lots of additional dialogue and commentary plus a new additional quest. She's now a follower with her own personal custom Archer-Assassin class and combat style with marriage potential. See the detailed description below for more.
[Skyrim] Generated Voice Pack for Nether's Follower Framework: https://www.nexusmods.com/skyrimspecialedition/mods/78890
I recently started using NFF and saw that there were several unvoiced dialog lines. This mod adds voices for them.
[Skyrim] In the Shadow of the Crown - No Stone Unturned Alternative: https://www.nexusmods.com/skyrimspecialedition/mods/79600
An alternative to "No Stone Unturned", this mod allows you to complete the Stones of Barenziah quest without involving the Thieves Guild.
[Skyrim] Ralof and Hadvar (On second thought..): https://www.nexusmods.com/skyrimspecialedition/mods/76548
Adds a sentence to both Ralof and Hadvar for continuity.
[Oblivion] XVASynth - AI Voice Imperial: https://www.nexusmods.com/oblivion/mods/52434
Imperial voice for Oblivion
[Mass Effect] The Hatboy Project - Joker is a Love Interest: https://www.nexusmods.com/masseffect3/mods/920/
This mod adds Joker as a romance option for FemShep players in Mass Effect 3. It adds new branches of fully voiced dialogue, scenes, and interactions. Joker and EDI remain platonic and interact accordingly.
[Fallout 4] Maxwell's World - Voiced Player Lines Addon: https://www.nexusmods.com/fallout4/mods/64100
Battle your way through Lakvan's Stronghold and claim it as your own. Fully voiced dungeon experience with references to TES Travels: Shadowkey.
[Oblivion] Lena's Companions for Tamriel and Morroblivion: https://www.nexusmods.com/oblivion/mods/52488
Custom companions based in Cyrodiil, Shivering Isles and Morroblivion using a common companion framework with extensive functionality. Each companion is unique and comes with its own ESP - mix and match as you like.
Support
The best support is using the tool, making something cool with it, and letting me know about it! Or spreading the word, to anyone that may get some use/fun out of this. Spread the word! Join the discord server, and let me know if you have any ideas/suggestions, show off something you made, or you just want to chat about all this: https://discord.gg/nv7c6E2TzV
Credits:
Big thank you to contributors who helped out on GitHub, and Discord:
- BunglePaws
- ionite
- Pendrokar
- RageRaptor
- dsp2003
Community asset files included natively in the app add support for games/game series. They were created by the following community members (non-exhaustive; if anything is incorrect/incomplete, let me know):
Assassin's Creed (Negomi)
Black and White (Bungles)
Diablo: (FluffyQuack)
Disney Infinity (LFE)
Dragon Ball (HappyPenguin)
Duke Nukem Forever (Negomi)
Elden Ring (Highlander)
Halo (Highlander)
Legacy of Kain (HappyPenguin)
Metal Gear Solid (tm888 & radbeetle)
Noone Lives Forever (Negomi)
Scrapland (dsp & HappyPenguin)
Shenmue (HappyPenguin)
Star Fox 64 (Highlander)
Tekken (HappyPenguin)
The Last of Us: (Radbeetle)
The Legend of Heroes (Wander Kusanagi & HappyPenguin)
Tomb Raider: (jj4379)
Vampire: The Masquerade (Highlander)
Zelda (Highlander)
Special thanks:
D0lphin, flyingvelociraptor, Caden Black, Max Loef, LadyVaudry, Thuggysmurf, radbeetle, TomahawkJackson, Solstice_, Bungles, midori95, eldayualien, John Detwiler, Cecell, Wandering Youth, ellia, Retlaw83, Trixie, CHASE MCKELVY, Leif, ionite, Joshua Jones, Jaktt1337, David Keith vun Kannon, Netherworks (Jo-Jo), neci, Rachel Wiles, Imogen, Deer, Linthar, sadfer, Danielle, Hector Medima, Sh1tMagnet, ReaperStoleMyStyle, AshbeeGaming, TCG, Lady Steel, Mikkel Jensen, CookieGalaxy, GrumpyBen, Adrilz, ReyVenom, dog, bourbonicRecluse, ShiningEdge, Dozen9292, manlethamlet, smokeandash, Elias V, EnculerDeTaMere, SKiLLsSoLoN, J, finalfrog, Hound740, Buck, Yael van Dok, ChrisTheStranger, Isabel, Fuzzy Lonesome, Drake, Beto, AceAvenger, bobbigmac, Alexandra Whitton, yic17, Joebobslim, ThatGuyWithaFace, Sergey Trifonov, Zensho, AgitoRivers, beccatoria, valo999, Ne0nFLaSH, Caro Tuts, Jack in the Hinter, Hammerhead96 ., Bewitched, Para, Wht??? Why??, Shadowtigers, PConD, Lulzar, Ryan W, Wyntilda, Gorim, Krazon, Tako-kun, Walt, Katsuki, Ember2528, RetconReality, Hazel Louise Steele, Laura Almeida, Althecow, PatronGuy, squirecrow, cramonty, crash blue, Syrr, David, Hawkbar, John S., Autumn, pimphat, FeralByrd, Comical, Dogmeat114, Dezmar-Sama, Michael Gill, Jacob Garbe, NerfViking, Dinonugget, RedneckJP007, stormalize, Golem, Luckystroker, Hapax, Vahzah Vulom, Tempuc, CAW CAW, stljeffbb, bart, MrJoy, Zoenna, Calvin, Aosana Bluewing, Dan Brookes, CDante, HunterAP, Kadisra, candied_skull, hairahcaz, nairaiwu, Mar, Paraffine, Nawen_Syaka, Amy Parker, Loseron, katiefraggle, Freon, deepbluefrog, myles.app, hanbonzan, Scientist Salari-Ren, Roman Tinkov, zackc1play, An abstract kind of horror, L, Mihu123, Trisket, Aelarr, Flipdark95, Timo Steiner, humocs, Optimist Vamscenes, Patrick VanDusen, praxis22, Rui Orey, Craig Fedynich, FrenchToast, Dorpz, cesm23, BoB, Cutup, Botty Butler, tjn2222, Matthew Warren, Tom Green, Passionate Lobster, Precipitation, Veks, Baki Balcioglu, Fenris, Patrik K., Oddbrother, E.M.A, DrogerKerchva, Camurai, hthek, iggyzee, Moppy, Stee_Muttlet, asbestos my beloved, TrueBlue, something106, woah00z, Sam Darling, JoshuaJSlone, vvvpppmmm, OvrTheTopMan, munchyfly, DarkNemphis, Justin McGough, Billyro, DIY_Rene, kevmasters, Stu, Sasquatch Bill, Inconsistent, Gothic 3 The Age of War, www48, Slothman, mavrodya petrov, ronaldomoon, Kostin Oleksandr Anatoliiovych, Ryan Lippen, Edward Hyde, Echoes, Vape Gwagwa, Kelg Celcs, Kneelers, Meryl Coker, Alan Gonzalez, PTC001, Hector Medima, CinnaMewRoll, Grant Spielbusch, Sean Lyons, Charles Hufnagel, Kirill Akimov, Mister Lyosea, Anthony Crane, Sh1tMagnet
All the amazing donors, anonymous or otherwise.
Adrian Łańcucki for FastPitch and the helpful discussions on GitHub.
All the amazing researchers behind the many tools and models I've used in creating this.
References
[1] FastPitch - ??https://arxiv.org/abs/2006.06873
[2] FastPitch 1.1 - ??https://arxiv.org/pdf/2108.10447.pdf
[3] CMUDict - http://www.speech.cs.cmu.edu/cgi-bin/cmudict
[4] HiFi GAN - ??https://arxiv.org/abs/2010.05646
[5] WaveGlow - ??https://arxiv.org/abs/1811.00002
[6] Tacotron2 - ??https://arxiv.org/abs/1712.05884
Changelog:
Changelog now moved to the changelog panel.
You can now train your own voices: xVATrainer
List of voices available for xVASynth, from both myself and the community: Google doc link
You can submit models at the following link, if you train them with xVATrainer: Google forms link
Quick intro
xVASynth is an AI based app for creating new voice lines using neural speech synthesis. The app loads models individually trained on character voice data from games. The app gives users control over details such as pitch and durations of individual letters to provide control over emotion and emphasis. To see it in action, watch these short intro/tutorial videos, narrated by various supported voices:
Supported games
- Skyrim (SKVASynth)
- Fallout 4 (F4VASynth)
- Oblivion (OBVASynth)
- Fallout New Vegas (NVVASynth)
- Morrowind (MWVASynth)
- Fallout 3 (F3VASynth)
- Starfield (SFVASynth) soon™
- Fallout 76 (F76VASynth)
- Cyberpunk 2077 (CPVASynth) <-- you are here
- Civilization (CIVVASynth)
- Mass Effect (MEVASynth)
- The Witcher (WVASynth)
- Humankind (HKVASynth)
- Dragon Age (DAVASynth)
- Overwatch (OWVASynth)
- and other games/series currently without a Nexus page (Final Fantasy, Borderlands, Bioshock, GTA 4, GTA 5, GTA:SA, Resident Evil, Red Dead Redemption 2, Command and Conquer, and others)
Discord: https://discord.gg/nv7c6E2TzV
Patreon: https://www.patreon.com/xvasynth
Twitter: @dan_ruta
Preface: The tool does not re-distribute any game assets, nor does it interact with them in any way. Game assets are used only during voice training as a reference, to guide the algorithm to drive itself to a point where it can create voices that sound similar enough to the examples. Think about it as an automated digital impersonator. Regardless, avoid using the tool in an offensive/explicit manner. Make it obvious where you can, in descriptions that the voice samples are generated, and are not from real human voice actors. Any issues you cause with this are on you.
Introduction
xVASynth is an AI app that generates voice acting lines using specific voices from video games. It can do text-to-speech (TTS) from text input, or voice conversion (VC) from audio input (file/microphone). Starting with v3, the app gives users artistic control over pitch, duration, energy, emotion, and style values for every letter in the audio. They also allow generating audio with explicitly defined pronunciation via ARPAbet [3] notation. Every v3 model can speak any of the 28 supported languages, and can switch between multiple languages in the same text prompt.
The use of neural speech synthesis leads to natural sounding voices, something which is very difficult to do with more traditional methods involving concatenations of existing data. It also means new vocabulary can be generated, outside of what the voice actors have already read out.
Voice Conversion (v3+)
The app can also do voice conversion, rather than text-to-speech. In this mode, you can provide a reference audio dialogue file, and the app will re-generate it but with the voice of the v3 model you select. You can provide a reference audio line by recording with your microphone (by clicking the icon), or you can drag+drop an audio file onto the icon. If needed (unlikely), you can control the voice conversion strength in the settings.
ARPAbet pronunciation (v2+)
You can specify exact pronunciation for words by using ARPAbet notation between { } brackets in the input, or by managing words in your own (or other people's) dictionaries. Included is CMUdict with 135k words with American-English pronunciations. NOTE: v3 introduces several new ARPAbet symbols, for a custom extended version of the ARPAbet spec which includes sounds more typically found in other languages.
Other 3rd party dictionaries you can install into the app include:
xVADict community project - Elder Scrolls edition: https://www.nexusmods.com/skyrimspecialedition/mods/56778
xVADict is a community project to create ARPAbet pronunciation dictionaries, for use in xVASynth. This page contains the dictionary for the unique words found across all Elder Scrolls games.
xVADict - Alphabet Pronunciation: https://www.nexusmods.com/skyrimspecialedition/mods/57439
Adds the English alphabet pronunciation to xVASynth.
Batch Mode
For larger projects, where you need to synthesize a large amount of lines, you can alternatively use the Batch synthesis mode. You can use either a .txt file or a .csv file to batch generate hundreds or even thousands of lines, in one go, with parallelization. Although the pitch/duration/energy editor is sometimes needed to get a line sounding just right, it's sometimes not needed, and this is a good way to get an initial pass on lines. Using the GPU is especially highly recommended for this, as you can greatly parallelize the number of lines generated in one go (limited by VRAM). You should also check the various settings, such as multi-threading, to get the best possible speed out of this for your system.
3D Voice embeddings visualizer
The 3D voice embeddings visualizer is an interactive panel where you can explore in 3D all the voices in the app, as seen by an AI representation learning model, projected down to 3D. There are no axes, and this serves purely as a visualization, to enable voice discovery. You can colour the points by game, or gender, and you can enable disable specific games/voices. You can load a voice by clicking it and the "Load" button, if it's installed.
Third party plugins
The app supports third-party plugins for either/both javascript front-end (UI) and python back-end (AI) parts of the app. Plugins are a great way to customise the app to your liking, or to add new functionality to it that would be too niche or too game-specific to add to the base app for everyone. Plugins can be made for either/both the front-end/back-end of the app. Some example plugins are listed here (let me know if you make anything, and I will add it here):
Voiced Player - xVASynth Fuz Ro Bork plugin: https://www.nexusmods.com/skyrimspecialedition/mods/62944
A plugin to connect xVASynth up to Fuz Ro Bork, enabling xVASynth voices to be used in the Fuz Ro Bork mod.
.lip and .fuz plugin for xVASynth v2: https://www.nexusmods.com/skyrimspecialedition/mods/55605
A plugin to create .lip and (optionally) .fuz files automatically from audio lines generated with xVASynth, in either normal mode or batch mode, with or without multi-threading. DOES NOT NEED THE CK. Works for Skyrim, Fallout 4, Fallout 3, and Fallout New Vegas.
xVASynth plugin - Romanian Language: https://www.nexusmods.com/skyrimspecialedition/mods/50878
A demo plugin for v1.4.0+ of xVASynth, where third party plugins are now supported. This plugin changes the app front-end, swapping the UI language to Romanian. Full developer reference: https://github.com/DanRuta/xVA-Synth/wiki/Plugins
If you are a developer and are interested in developing a plugin, check out the documentation here: https://github.com/DanRuta/xVA-Synth/wiki/Plugins
Nexus API integration
xVASynth has Nexusmods API integration to display what voices are available for updates/download, from any of the nexus pages listed in the "Manage Repos" sub-menu. If you have Nexus Premium, you can also download or batch download voices straight from within the app, and have them installed automatically.
App installation
You may need to install Microsoft Visual C++ Redistributable if you don't already have it. To install the app, download it and extract it anywhere you'd like (it does not need to be in any game directory). Launch the app by double-clicking the xVASynth.exe file. If you have any issues, try running it as admin, but be mindful that Electron on Windows has some issues with drag+drop events when running as Admin.
NOTE: v3 voices do not use a separate vocoder, as they are all-in-one models. You do not need/cannot use HiFi-GAN or WaveGlow models with v3 models
Important: Make sure you click "Allow" if windows asks you for permission to run the python server. I use a local HTTP server to enable communication between the python code (for the AI models) and the JavaScript code (for the Electron front-end). If there are any issues, check the server.log/app.log files (located next to xVASynth.exe) - there should be an error at the end which I'll need to see for helping with issues.
Voice installation
The recommended way to install voices is through the Nexus API integration. However, if you don't have Nexus Premium membership, or you'd prefer manual installation, you need to download the individual .zip files from the game-specific nexus pages (such as this one). You can either drag+drop these over the voice bar on the left in the app, or extract the voice files into the app directory, at this location: <.exe location>/resources/app/models/<game> where <game> is the game ID. The voice .zip files already contain the required directory structure, so all you need to do is drag+drop the extracted "resources" folder from the .zip files into the folder where the xVASynth.exe file is (replacing files if prompted).
To confirm, when installing voices, you should see 3 or 4 files (a .json, a .pt, a .hg.pt, and a .wav file) all named as the voice you're downloading, in <your xVASynth install directory>/resources/app/models/<game>/ (where <game> is cyberpunk, for models on this page).
Important: If you move the app files to a different directory, you MUST update the model paths in the settings, because these folder paths get initialized with the full path (starting from the drive letter) - basically, just make sure the app is looking in the new place where your models are, rather than the old folder. The app also allows you to set a different folder to store your voice models in, rather than nested in your app installation directory. The easier thing to do long-term would be to find somewhere not in your app installation folder to store your models, and set the app file paths to point there.
The voices
For Cyberpunk, the voices trained so far are as follows ("Track" the mod for updates):
v3 models:
- V (Male)
- Johnny
- Judy
- Panam
- Kerry
- River
Older:
- ? ? Claire
- ? ? Alt
- ? ? Delamain
- ? ? Takemura
- ? ? Misty
- ? ? Placide
- ? ? Jackie
- ? ? Elizabeth
- ? ? Sebastian
- ? ? Rhino
- ☢ ? Rogue
- ☢ ? Evelyn
- ☢ ? Haru
- ☢ ? Dakota
- ☢ ? Gillean
- ☢ ? Wakako
- ☢ ? Hanako Arasaka
- ☢ ? Stanley
- ☢ ? Lizzy Wizzy
- ☢ ? Meredith Stout
- ☢ ? Maiko
- ☢ ? Rachel
Where green text colour represents good quality, yellow means ok quality, and red currently quite bad (will need a good deal of playing with the input to get something good). There are several types of models and variants of models supported by the app, so I will use emojis to try to clearly label what type of model each voice is:
? - This means the data for the voice is pre-trained using Tacotron2 [6], and the sentence structure/composition quality will be high
? - This means the voice comes with a bespoke HiFi [4] vocoder model, meaning the audio quality will be high
☢ - This means the voice model is FastPitch1.1, enabling energy control, speech-to-speech, and ARPAbet pronunciation. Tacotron2 isn't needed for this. (rad icon for RAD-TTS the built-in alignment mechanism replacing Tacotron2)
Note: To start with, most voice models will be v1.0 FastPitch, but they will eventually all be re-trained with the better v2.0 models with all the new features. I have over 425 voices to get through, so it may take a while.
You can optionally install WaveGlow [5] models from here, for extra vocoder options, but these are much slower, and almost always not as good as HiFi-GAN.
Tips
The most important thing to keep in mind is to make sure to play around with the editor, to get the best quality from the generated lines. If some words/letters sound bad, try changing the pitch/duration/energy values. Tinny artefacts can normally be fixed by slightly shortening the durations of offending letters. If you absolutely can't get it to say it well, and ARPAbet pronunciation doesn't help, try re-wording the line.
Check out the community guide here, where anyone can add their tips/advice for how to get the best quality out of the tool: https://github.com/DanRuta/xvasynth-community-guide You can also access this from the info (i) menu in the app.
Downstream uses
If you make anything with this tool (mod or otherwise), let me know and I will include it here.
YouTube playlist of xVA experiments (WaveGlow MaleSlyCynical): https://www.youtube.com/playlist?list=PLDGgH-fuVvfa8-HFdSi7ls1ykLIuquIpD
Radio New Vegas GPT-3: https://bunglepaws.neocities.org/radio_new_vegas_gpt3.html
[Fallout 4] Fallout 4 Point Lookout - Voiced Player Lines Addon: https://www.nexusmods.com/fallout4/mods/60387
XVASynth generated voice lines for Nate and Nora in the Fallout 4 Point Lookout mod.
[Fallout 4] Flashy(JoeR) - Gun For Hire - Commonwealth Mercenary Jobs: https://www.nexusmods.com/fallout4/mods/49610
Gun For Hire allows you to open a business outside of Diamond City and to run never-ending jobs for clients from a base of 27 different archetypes.
[Skyrim] Auto Sleep For Me Now: https://www.nexusmods.com/skyrimspecialedition/mods/56850
The most vanilla follower detect player auto sleep ever
[Skyrim] Sit For Me Now: https://www.nexusmods.com/skyrimspecialedition/mods/57423
Your follower auto sits with you
[Skyrim] Me So Hungry: https://www.nexusmods.com/skyrimspecialedition/mods/57184
NPCs cooking
[Fallout New Vegas] Easy Lanius: https://www.nexusmods.com/newvegas/mods/74565
Replaces Easy Pete's voice with a Lanius voice created by xVASynth2.
The Monster of the East has come to Goodsprings to retire.
[Skyrim] Teldryn Sero Dialogue Expansion: https://www.nexusmods.com/skyrimspecialedition/mods/42434
More unique dialogue for Teldryn Sero -- Adds conditional commentary and some player dialogue options.
[Oblivion] Oblivion Nouveau Uncut: https://www.nexusmods.com/oblivion/mods/47191
Adds over 50 npcs, 6 side quests & 1 questline, voiced Nord & Redguard guards, new locations & items, over 1000 lines of dialogue and much more!
[Oblivion] Chapter II - Daggerfall 3E433: https://www.nexusmods.com/oblivion/mods/49031
Welcome to the Kingdom of Daggerfall, Experience the entirety of Hammerfell & High Rock recreated lore friendly with Chapter II Content
[Fallout 4] Isran (Skyrim) Male Protagonist Voice Replacer: https://www.nexusmods.com/fallout4/mods/56972
Bored with the generic male protagonist voice? Don't like him saying sarcastic lines in an exaggerated way? Want to make a tough-looking character but the voice just doesn't cut it for you? This mod is for you! It replaces the male protagonist's voice with Isran's voice, making your character actually sound tough and threatening (and serious).
[Skyrim] The Courier Crew: https://www.nexusmods.com/skyrim/mods/110453
Adds two additional couriers w/ all courier voice lines for a total of three couriers
[Cyberpunk 2077] All Rhino All the Time: https://www.nexusmods.com/cyberpunk2077/mods/2826
Complete AUDIO AND VISUAL overhaul for various characters into the large muscular beauty, Rhino. Some have options for new skin, hair, and clothes, and some also have reworked female voices (via CPVA Synth).
[Skyrim] Phenderix Magic World: https://www.nexusmods.com/skyrimspecialedition/mods/6551
Phenderix Magic World adds a massive amount of content including new spells, weapons, bosses, followers, locations, and much more! Download today to unleash hundreds of new roleplaying options and discover a new world where magic has just begun to awaken.
[Skyrim] Wedding Outfit Commission: https://www.nexusmods.com/skyrimspecialedition/mods/52032/
Getting married? Commission wedding outfits for yourself and your spouse from Radiant Raiment! Now you and your betrothed can get hitched in style. (Fully voiced with brand new immersive dialog created using xVASynth)
[Skyrim] I'm Glad You're Here - a follower and spouse appreciation mod: https://www.nexusmods.com/skyrimspecialedition/mods/41856 (LE)
Allows the player to show their appreciation to their followers, spouse and adopted kids by dialogue and a hug animation. Voiced with vanilla assets.
[Skyrim] Less Generic Housecarls - Argis (Markarth) Dialogue Expansion and Quest: https://www.nexusmods.com/skyrimspecialedition/mods/48194/
Dialogue expansion and personal quest for Argis the Bulwark, your Markarth housecarl.
[Skyrim] Afterlife - Resurrected: https://www.nexusmods.com/skyrimspecialedition/mods/55051
Afterlife for NPCs is back! Valiant Nords will go to Sovngarde, while soul trapped characters will be sent to the Soul Cairn, upon death.
[Skyrim] VASynth Follower Dialogue Pack: https://www.nexusmods.com/skyrimspecialedition/mods/62488
This provides new voices to be used when creating follower NPCs.
[Fallout New Vegas] A World Of Speechless Pain - xVASynth NPC Voice: https://www.nexusmods.com/newvegas/mods/74992
A experimental mod which added voice for a few AWOP NPC, created by the tool which available for everyone.
[Skyrim] Voices of the Legendary Cities: https://www.nexusmods.com/skyrimspecialedition/mods/61634
Add voices generated with xVASynth 2 to all dialogues in the mod Legendary Cities - Tes Arena - Skyrim Frontier Fortress
[Skyrim] Maven Follower and Spouse Add-on: https://www.nexusmods.com/skyrimspecialedition/mods/61034
Turns Maven Black-Briar into a fully functional potential follower, spouse, "flower girl", and a much more likeable character overall. 350+ new fully voiced lines of dialogue, based on existing spliced audio and xVASynth-generated samples. Also turns Ingun into potential follower and spouse after you complete her quest.
[Skyrim] Blood on the Ice- Wuunferth Dialog Fix: https://www.nexusmods.com/skyrimspecialedition/mods/56378
Fixes a couple of inconsistencies with Wuunferth's dialogue during the quest 'Blood on the Ice'. ESL- flagged!
[Skyrim] Dovahsil - Alduin's Faction: https://www.nexusmods.com/skyrimspecialedition/mods/51231
This mod is designed to add another option to the end of the main quest: Siding with Alduin, burning down Sovngarde, and destroying the Blades.
[Skyrim] Dealing with Daedra: https://www.nexusmods.com/skyrimspecialedition/mods/40494 (LE)
Warlock style magic systems and new factions. Magic systems offer power for a price to non-mage characters. New factions provide "quests" and gameplay hubs. Aimed at creating new character build opportunities.
[Fallout 4] Nuka-World Reborn: https://www.nexusmods.com/fallout4/mods/32857?
Nuka-World Reborn is a quest mod which not only allows you to have multiple options to get rid of the raiders, but it adds new questlines to Nuka-World and allows you to play as a Trader.
[Fallout 4] Viva Nuka-World: https://www.nexusmods.com/fallout4/mods/37356
The sequel to Nuka-World Reborn - Viva Nuka-World is set after the events of Nuka-World Reborn, offering a more rigid quest design, more detailed dialogue scenes, configuration options and more...
[Skyrim] Positive Undressed Reactions: https://www.nexusmods.com/skyrimspecialedition/mods/44334
New lore-friendly voiced reactions to the player being undressed, using xVASynth, unused lines and splicing.
[Skyrim] Daejanggeum: https://www.nexusmods.com/skyrimspecialedition/mods/52518/
1. ESL, Fully voiced perfect healer, main quest helper. 2. There are story quests. and light scripts(never heavy). 3. Lite mod with only heals, no voice, no script at all.
[Skyrim] The Windhelm Smelterworks: https://www.nexusmods.com/skyrimspecialedition/mods/46333
The Windhelm Smelterworks adds an industrial scale smelterworks outside Windhelm, bringing some depth and immersiveness to Skyrim’s heavily mining dependent economy
[Skyrim] Cait in Skyrim: https://www.nexusmods.com/skyrimspecialedition/mods/44982
Bring Cait from Fallout 4 to Skyrim. Fully voiced using Cait's voice! Currently has 79 voiced lines. I've recreated a number of the original lines from Fallout, some "tweaked" ;) and a LOT of new lines!
[Skyrim] The Elder Scrolls Legends Imports: https://www.nexusmods.com/skyrimspecialedition/mods/32104
Adds references to Elder Scrolls: Legends cards and story into the world of Skyrim.
[Oblivion] NewCity_SI_Passwall_ENG: https://www.nexusmods.com/oblivion/mods/50837
Here you have the Russian mod NewCity Passwall, fully translated into English
[Skyrim] Ysolda Roasts Jon: https://www.nexusmods.com/skyrimspecialedition/mods/44630
Recreates the famous "Lamar Roasts Franklin" scene with a skyrim flavor using Ysolda and Jon Battle Born
[Skyrim] Dyudyaev-Kun: https://www.nexusmods.com/skyrimspecialedition/mods/44753
Adds a Male Woodelf dragonborn to your game.
He is a custom voice follower based on the Male young eager voice. ( use SKVA Synth)
[Skyrim] Nether's Frea: https://www.nexusmods.com/skyrimspecialedition/mods/49018
A complete overhaul to Frea including new voiced dialogue, quest and location awareness, dynamic lines from player actions, npc interaction, combat enhancements, new abilities, non-combat bonuses, customized skin, sculpted face and more! A Frea overhaul like you've never seen before.
[Skyrim] Nether's Karliah: https://www.nexusmods.com/skyrimspecialedition/mods/49334
A complete overhaul to Karliah including new voiced dialogue, quest and location awareness, dynamic lines from player actions, npc interaction, combat enhancements, new abilities, non-combat bonuses, customized skin, sculpted face and more! A Karliah overhaul like you've never seen before.
[Skyrim] Nether's Eola: https://www.nexusmods.com/skyrimspecialedition/mods/57250
A wickedly macabre, darkly humorous re-imagination of Skyrim's Eola. Features an enhanced, tweaked follower with plenty of options, an additional follower by the way of Nimphaneth (wood elf cannibal necromancer), extensive idle interactions between Eola and Nimph (if you use them both), harvesting of "tasty meat" from humanoids and MUCH MORE!
[Skyrim] Bards Reborn Student of Song Become a Bard Expansion with Bard Spells:https://www.nexusmods.com/skyrimspecialedition/mods/47994
This mod give the Bards College a massive makeover, adds a new study quest, new bardic spells, and a new character to flesh out your experience as a Bard. It includes all the great features of Become a Bard and expands on their use in the game.
[Skyrim] Authentic Sinding Follower SE: https://www.nexusmods.com/skyrimspecialedition/mods/33517
Gives Sinding a whole visual makeover and makes him a potential follower if you decided to help him during the Daedric quest "Ill Met by Moonlight".
[Skyrim] Susena Steel-Wolf Follower: https://www.nexusmods.com/skyrimspecialedition/mods/49493
Add Susena Steel-Wolf to Skyrim. She is staying at the Silver-Blood Inn in Markarth. She is the toughest mercenary in Skyrim. She has additional voices using SKVA Synth - xVASynth and has as much dialogue as Teldryn Sero. Her voice type is FemaleYoungEager.
[Skyrim] Random Guard Dialogues: https://www.nexusmods.com/skyrimspecialedition/mods/44378
New funny and random voiced dialogues for guards made with xVA-Synth
[Skyrim] Nazeem as a Follower: https://www.nexusmods.com/skyrim/mods/107792/
Nazeem as a follower, but with the assistance of XVASynth to give him voiced dialogue.
[Morrowind] Voicelines for Nord Fighters Guild Males: https://www.nexusmods.com/morrowind/mods/50105
Voicelines for Nord males of the Fighters Guild. They will address you as Journeyman to Master with different lines depending on your disposition.
[Skyrim] Stop right there criminal scum: https://www.nexusmods.com/skyrimspecialedition/mods/44181
A mod to add the infamous Oblivion line to Skyrim guards
[Skyrim] Female Hirelings: https://www.nexusmods.com/skyrimspecialedition/mods/48795
There is only one female Hireling in Skyrim. This makes *all* of them female (just Belrand atm). Fully voiced with natural looking faces.
[Skyrim] Trigger King Olaf's Festival Any Day - With Proper Ending SE: https://www.nexusmods.com/skyrimspecialedition/mods/46766
With this mod you can tell Viarmo to spontaneously arrange a festival on the same night. Also makes sure that each festival will automatically end at 4AM
[Skyrim] Your Choices Matter - A Dark Brotherhood Expansion: https://www.nexusmods.com/skyrimspecialedition/mods/46871 (LE)
This mod extends the Dark Brotherhood questline in many ways and adds an optional alternate ending. The ending you get will depend on the choices you, the Player make, throughout the story. Completely voiced dialogues, using vanilla and xVASynth assets.
[Skyrim] Adoption without Murder (Innocence Lost for Good Guys): https://www.nexusmods.com/skyrimspecialedition/mods/46741
A tongue-in-cheek alternative solution for Innocence Lost, for when you maybe want to adopt an orphan but without all that murder and stuff.
[Skyrim] Female Hirelings: https://www.nexusmods.com/skyrimspecialedition/mods/48795
There is only one female Hireling in Skyrim. This makes *all* of them female (just Belrand atm). Fully voiced with natural looking faces.
[Skyrim] M'aiq The Liar Anniversary Edition (aka Modder's Edition): https://www.nexusmods.com/skyrimspecialedition/mods/58958
Adds additional quirky not-quite-but-almost-fourth-wall-breaking dialogue lines to M'aiq the Liar celebrating 10 years of modding Skyrim.
[Skyrim] Thogra gra-Mugur - Orc Follower and Quest: https://www.nexusmods.com/skyrimspecialedition/mods/58979
Help an Orc widow get revenge on the one who wronged her. Multiple body options, custom dialogues, a quest with different endings, and more! Compatible with SE and AE.
[Skyrim] Fjotra Sybil of Dibella as a Young Adult: https://www.nexusmods.com/skyrimspecialedition/mods/56877
The new Sybil of Dibella is now a young adult, fully voiced and with a new quest.
[The Witcher 3] New Quest - Strange things: https://www.nexusmods.com/witcher3/mods/6156
New story about Ciri from another world.
Created using Radish Modding Tools.
P.S. My amateur quest.
[Skyrim] Serana Relationship Revamped: https://www.nexusmods.com/skyrimspecialedition/mods/59341
A mod that aims to enhance Serana as a character and her relationship with the player character. The intent is to stay as faithful to Bethesda's original rendition while exploring new avenues of conversation and a gradually evolving relationship, either platonic or romantic which is based on how the player character interacts with her.
[Skyrim] Flashy(JoeR) - Lydia Redefined - An Advanced Follower System: https://www.nexusmods.com/skyrimspecialedition/mods/62795
Lydia: Redefined provides a parallel follower system to significantly enhance adventuring with (nearly) everyone's favorite housecarl.
[Mass Effect] Nobody Cheated: https://www.nexusmods.com/masseffectlegendaryedition/mods/1032
This is the Legendary Edition version of the existing mod, Nobody Cheated. This mod allows a Female Shepard that had a romance in LE2 to respond to Kaidan when he accuses her of cheating.
[Fallout 4] Karliah (Skyrim) Female Protagonist Voice Replacer (British Accent): https://www.nexusmods.com/fallout4/mods/58235
Replaces the female protagonist's voice with the voice of Karliah from Skyrim. Karliah's voice is unique and she speaks in a British accent in Skyrim. Give your new character a new personality with this voice replacer mod!
[Fallout 4] Talk Like Arnie - Terminator Parody Mod: https://www.nexusmods.com/fallout4/mods/59275
This mod will replace the voice of the main protagonist with a new voice that closely resembles that of a Terminator Arnold Schwarzenegger. Many dialog lines in the game are also replaced with one-liners and memes like "Get to the choppa!" or "Hasta la vista, baby!" For female protagonists, your voice now resembles TSSC's Cameron (Summer Glau).
[Fallout 4] Nuka World Plus: https://www.nexusmods.com/fallout4/mods/31164
One of the main concerns from players of the "Nuka-World" DLC was
that as a good Player, there isn't much to do in Nuka-World after completing the quest, "open season". I
want to change that!
[Skyrim] Philmorex - A Rideable Steerable Dragon Follower: https://www.nexusmods.com/skyrimspecialedition/mods/63338
Philmorex is a rideable, steerable dragon follower. He will accompany you in your travels, and will assist you in your battles - aside you, or while you are riding him. Use intuititve commands to fully control your flight. Call for him again at any time after you have asked him to wait or leave, and Philmorex will return to you.
[Skyrim] Cutting Room Floor - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66278
Add new greeting dialogues for some NPCs from Cutting Room Floor using xVASynth2.
[Skyrim] Glenmoril and Unslaad xVASynth Voiced: https://www.nexusmods.com/skyrimspecialedition/mods/65959
used xVASynth 2 to generate voiced lines for Glenmoril and Unslaad
[Fallout 4] Cait (Fallout 4) Female Protagonist Voice Replacer (Irish-ish accent): https://www.nexusmods.com/fallout4/mods/59308
Replaces the player's voice with Cait's voice from Fallout 4. Live as an Irish lass in the Commonwealth!
[Fallout 4] Carl Johnson (CJ) in Fallout 4 - Voice replacer and face preset: https://www.nexusmods.com/fallout4/mods/60119
This mod brings Carl Johnson (CJ) from GTA San Andreas as a playable character in Fallout 4. The voice is replaced via xVASynth, and the face preset can be loaded via Looksmenu.
[Skyrim] Say my name: https://www.nexusmods.com/skyrimspecialedition/mods/56774
Say my name changes game lines to make NPCs actually speak out (audio) your character's custom name, instead of referring to you as "Dragonborn". Audio generated via xVASynth.
[Skyrim] Oakwood - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66971
Added new greeting lines for NPCs from Oakwood mod, voices generated by xVASynth2.
[Skyrim] Fishing - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67053
Improved the narrative of Fishing questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] M.E.I. - Maven Elenwen Ingun - Followers and Spouses Add-on: https://www.nexusmods.com/skyrimspecialedition/mods/61034
Turns Maven, Elenwen and Ingun into fully functional potential followers, spouses, and a much more likeable characters overall. 750+ new fully voiced lines of dialogue, based on existing spliced audio and xVASynth-generated samples.
[Skyrim] iNeedy: https://www.nexusmods.com/skyrimspecialedition/mods/67475
a Vocal compliment to Isoku's iNeed
[Skyrim] Redguard Elite Armaments - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67532
Improved the narrative of Interception quest from Redguard Elite Armaments with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] The Gray Cowl Returns - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67439
Improved the narrative of The Gray Cowl Returns quest with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Ghosts of the Tribunal - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67374
Improved the narrative of Ghosts of the Tribunal questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Saints and Seducers - Voiced Narrative: https://www.nexusmods.com/skyrimspecialedition/mods/67117
Improved the narrative of Saints & Seducers questline with new voiced dialogues carefully generated by xVASynth2.
[Skyrim] Shor's Stone - Voiced NPCs: https://www.nexusmods.com/skyrimspecialedition/mods/66454
Add new greeting dialogues for NPCs added by Shor's Stone mod using xVASynth2.
[Skyrim] Darkwater Crossing - Voiced Meieran: https://www.nexusmods.com/skyrimspecialedition/mods/66393
Add new greeting dialogues for Meieran from Darkwater Crossing mod using xVASynth2.
[Skyrim] Companion Yngvarr SE: https://www.nexusmods.com/skyrimspecialedition/mods/32048
An old Nord warrior longing for Sovngarde, cursed by beast blood.
Custom voiced using and editing Kodlak Whitemanes voice, unused dialogue and xVASynth. SE port.
[Skyrim] Mistborn - An Immersive Follower Collection: https://www.nexusmods.com/skyrimspecialedition/mods/67896
An immersive follower collection with intro quests, custom dialogue, and additional follower features, such as training and spell teaching.
(This is NOT based on Brandon Sanderson's "Mistborn" series.)
[Skyrim] EVG Animated Traversal: https://www.nexusmods.com/skyrimspecialedition/mods/63232
A framework to add new animation prompts for the player to climb ledges, squeeze in tight spaces, jump over walls and more.
[Skyrim] Jed The Guard Voiced NPC: https://www.nexusmods.com/skyrimspecialedition/mods/69627
Jed is a lazy, grumpy guard who is jaded by decades of guard duty and comes with a custom voice created with xVASynth. Contains some adult dialogue and humour which some may find offensive. ESL flagged.
[Fallout 4] Keanu Reeve's Voice Replacer for Male Protagonist: https://www.nexusmods.com/fallout4/mods/61252
Replaces Fallout 4's male protagonist's voice with Keanu Reeve's voice using the model of Johnny Silverhand from Cyberpunk 2077. Now you can finally play a John Wick playthrough!
[Skyrim] Guards Found Your Sweet Roll: https://www.nexusmods.com/skyrimspecialedition/mods/71697/
Guards will occasionally give you a sweet roll. A random chance, will happen only if you don't already have one in your inventory.
Fully voiced with spliced and xVA-generated lines. ESP-FE.
[Skyrim] Remiel-Custom Voiced Dwemer Specialist and Companion: https://www.nexusmods.com/skyrimspecialedition/mods/51874
Adds Remiel to your game, custom voiced with ~2500 lines of dialogue, a Breton engineer who will accompany you in your travels. She's travelled from Wayrest to explore dwemer ruins in Skyrim, but she needs your help. While she's not much of a fighter, she boasts a knack for machinery and will reprogram a dwemer spider to fight alongside you both.
[Skyrim] Breakable Equipment System: https://www.nexusmods.com/skyrimspecialedition/mods/23686
Another equipment break/degradation mod. Compatible with ALL well-made weapon/armor mods. Compatible with ALL armor slots. Compatible with PC and NPCs. Broken equipment can be repaired at grindstone or workbench. Equipment in NPCs' inventory, equipment in containers and eqiupment placed at habitable area are randomly temper
[Skyrim] Love and Expectations - The Story of Olfina Gray-Mane and Jon Battle-Born (Voiced with xVASynth): https://www.nexusmods.com/skyrimspecialedition/mods/72003
Love and Expectations adds a new questline focusing on Olfina Gray-Mane and Jon Battle-Born with a greater focus on player choice and outcomes. Will you help Olfina and Jon keep their secret? Or will you tell their families? Contains 1 quest with 2 optional following quest.
[Oblivion] Companion Arren - voiced: https://www.nexusmods.com/oblivion/mods/52203
The companion mod Arren by Sein_Schatten has over 3000 lines of dialogue, but sadly lacked voice, although silent voice files were present for all conversations. Here are all voice files.
[Skyrim] Lakvan's Stronghold - Shadowkey Dungeon and Player Home: https://www.nexusmods.com/skyrimspecialedition/mods/71084
Battle your way through Lakvan's Stronghold and claim it as your own. Fully voiced dungeon experience with references to TES Travels: Shadowkey.
[Oblivion] Mods Aware M'aiq (MAM) and fish stick dialogue fix: https://www.nexusmods.com/oblivion/mods/52418/
This mod makes M'aiq the Liar aware of your installed mods and adds up to 109 new VOICED dialogues to M'aiq the Liar, depending on the mods you have installed. Some vanilla dialogues can be also removed depending on your mods. It also fixes vanilla dialogue about fish sticks.
[Skyrim] Katria: https://www.nexusmods.com/skyrimspecialedition/mods/59966
This mod is a complete overhaul for the vanilla Katria. Her vanilla voice has been completely replaced. Includes lots of additional dialogue and commentary plus a new additional quest. She's now a follower with her own personal custom Archer-Assassin class and combat style with marriage potential. See the detailed description below for more.
[Skyrim] Generated Voice Pack for Nether's Follower Framework: https://www.nexusmods.com/skyrimspecialedition/mods/78890
I recently started using NFF and saw that there were several unvoiced dialog lines. This mod adds voices for them.
[Skyrim] In the Shadow of the Crown - No Stone Unturned Alternative: https://www.nexusmods.com/skyrimspecialedition/mods/79600
An alternative to "No Stone Unturned", this mod allows you to complete the Stones of Barenziah quest without involving the Thieves Guild.
[Skyrim] Ralof and Hadvar (On second thought..): https://www.nexusmods.com/skyrimspecialedition/mods/76548
Adds a sentence to both Ralof and Hadvar for continuity.
[Oblivion] XVASynth - AI Voice Imperial: https://www.nexusmods.com/oblivion/mods/52434
Imperial voice for Oblivion
[Mass Effect] The Hatboy Project - Joker is a Love Interest: https://www.nexusmods.com/masseffect3/mods/920/
This mod adds Joker as a romance option for FemShep players in Mass Effect 3. It adds new branches of fully voiced dialogue, scenes, and interactions. Joker and EDI remain platonic and interact accordingly.
[Fallout 4] Maxwell's World - Voiced Player Lines Addon: https://www.nexusmods.com/fallout4/mods/64100
Battle your way through Lakvan's Stronghold and claim it as your own. Fully voiced dungeon experience with references to TES Travels: Shadowkey.
[Oblivion] Lena's Companions for Tamriel and Morroblivion: https://www.nexusmods.com/oblivion/mods/52488
Custom companions based in Cyrodiil, Shivering Isles and Morroblivion using a common companion framework with extensive functionality. Each companion is unique and comes with its own ESP - mix and match as you like.
Support
The best support is using the tool, making something cool with it, and letting me know about it! Or spreading the word, to anyone that may get some use/fun out of this. Spread the word! Join the discord server, and let me know if you have any ideas/suggestions, show off something you made, or you just want to chat about all this: https://discord.gg/nv7c6E2TzV
Credits:
Big thank you to contributors who helped out on GitHub, and Discord:
- BunglePaws
- ionite
- Pendrokar
- RageRaptor
- dsp2003
Community asset files included natively in the app add support for games/game series. They were created by the following community members (non-exhaustive; if anything is incorrect/incomplete, let me know):
Assassin's Creed (Negomi)
Black and White (Bungles)
Diablo: (FluffyQuack)
Disney Infinity (LFE)
Dragon Ball (HappyPenguin)
Duke Nukem Forever (Negomi)
Elden Ring (Highlander)
Halo (Highlander)
Legacy of Kain (HappyPenguin)
Metal Gear Solid (tm888 & radbeetle)
Noone Lives Forever (Negomi)
Scrapland (dsp & HappyPenguin)
Shenmue (HappyPenguin)
Star Fox 64 (Highlander)
Tekken (HappyPenguin)
The Last of Us: (Radbeetle)
The Legend of Heroes (Wander Kusanagi & HappyPenguin)
Tomb Raider: (jj4379)
Vampire: The Masquerade (Highlander)
Zelda (Highlander)
Special thanks:
D0lphin, flyingvelociraptor, Caden Black, Max Loef, LadyVaudry, Thuggysmurf, radbeetle, TomahawkJackson, Solstice_, Bungles, midori95, eldayualien, John Detwiler, Cecell, Wandering Youth, ellia, Retlaw83, Trixie, CHASE MCKELVY, Leif, ionite, Joshua Jones, Jaktt1337, David Keith vun Kannon, Netherworks (Jo-Jo), neci, Rachel Wiles, Imogen, Deer, Linthar, sadfer, Danielle, Hector Medima, Sh1tMagnet, ReaperStoleMyStyle, AshbeeGaming, TCG, Lady Steel, Mikkel Jensen, CookieGalaxy, GrumpyBen, Adrilz, ReyVenom, dog, bourbonicRecluse, ShiningEdge, Dozen9292, manlethamlet, smokeandash, Elias V, EnculerDeTaMere, SKiLLsSoLoN, J, finalfrog, Hound740, Buck, Yael van Dok, ChrisTheStranger, Isabel, Fuzzy Lonesome, Drake, Beto, AceAvenger, bobbigmac, Alexandra Whitton, yic17, Joebobslim, ThatGuyWithaFace, Sergey Trifonov, Zensho, AgitoRivers, beccatoria, valo999, Ne0nFLaSH, Caro Tuts, Jack in the Hinter, Hammerhead96 ., Bewitched, Para, Wht??? Why??, Shadowtigers, PConD, Lulzar, Ryan W, Wyntilda, Gorim, Krazon, Tako-kun, Walt, Katsuki, Ember2528, RetconReality, Hazel Louise Steele, Laura Almeida, Althecow, PatronGuy, squirecrow, cramonty, crash blue, Syrr, David, Hawkbar, John S., Autumn, pimphat, FeralByrd, Comical, Dogmeat114, Dezmar-Sama, Michael Gill, Jacob Garbe, NerfViking, Dinonugget, RedneckJP007, stormalize, Golem, Luckystroker, Hapax, Vahzah Vulom, Tempuc, CAW CAW, stljeffbb, bart, MrJoy, Zoenna, Calvin, Aosana Bluewing, Dan Brookes, CDante, HunterAP, Kadisra, candied_skull, hairahcaz, nairaiwu, Mar, Paraffine, Nawen_Syaka, Amy Parker, Loseron, katiefraggle, Freon, deepbluefrog, myles.app, hanbonzan, Scientist Salari-Ren, Roman Tinkov, zackc1play, An abstract kind of horror, L, Mihu123, Trisket, Aelarr, Flipdark95, Timo Steiner, humocs, Optimist Vamscenes, Patrick VanDusen, praxis22, Rui Orey, Craig Fedynich, FrenchToast, Dorpz, cesm23, BoB, Cutup, Botty Butler, tjn2222, Matthew Warren, Tom Green, Passionate Lobster, Precipitation, Veks, Baki Balcioglu, Fenris, Patrik K., Oddbrother, E.M.A, DrogerKerchva, Camurai, hthek, iggyzee, Moppy, Stee_Muttlet, asbestos my beloved, TrueBlue, something106, woah00z, Sam Darling, JoshuaJSlone, vvvpppmmm, OvrTheTopMan, munchyfly, DarkNemphis, Justin McGough, Billyro, DIY_Rene, kevmasters, Stu, Sasquatch Bill, Inconsistent, Gothic 3 The Age of War, www48, Slothman, mavrodya petrov, ronaldomoon, Kostin Oleksandr Anatoliiovych, Ryan Lippen, Edward Hyde, Echoes, Vape Gwagwa, Kelg Celcs, Kneelers, Meryl Coker, Alan Gonzalez, PTC001, Hector Medima, CinnaMewRoll, Grant Spielbusch, Sean Lyons, Charles Hufnagel, Kirill Akimov, Mister Lyosea, Anthony Crane, Sh1tMagnet
All the amazing donors, anonymous or otherwise.
Adrian Łańcucki for FastPitch and the helpful discussions on GitHub.
All the amazing researchers behind the many tools and models I've used in creating this.
References
[1] FastPitch - ??https://arxiv.org/abs/2006.06873
[2] FastPitch 1.1 - ??https://arxiv.org/pdf/2108.10447.pdf
[3] CMUDict - http://www.speech.cs.cmu.edu/cgi-bin/cmudict
[4] HiFi GAN - ??https://arxiv.org/abs/2010.05646
[5] WaveGlow - ??https://arxiv.org/abs/1811.00002
[6] Tacotron2 - ??https://arxiv.org/abs/1712.05884
Changelog:
Changelog now moved to the changelog panel.