xVATrainer is the companion app to xVASynth, the AI text-to-speech app using video game voices. xVATrainer is used for creating the voice models for xVASynth, and for curating and pre-processing the datasets used for training these models. With this tool, you can provide new voices for mod authors to use in their projects.
Other user's assetsAll the assets in this file belong to the author, or are from free-to-use modder's resources
Upload permissionYou are not allowed to upload this file to other sites under any circumstances
Modification permissionYou must get permission from me before you are allowed to modify my files to improve it
Conversion permissionYou are not allowed to convert this file to work on other games under any circumstances
Asset use permissionYou must get permission from me before you are allowed to use any of the assets in this file
Asset use permission in mods/files that are being soldYou are not allowed to use assets from this file in any mods/files that are being sold, for money, on Steam Workshop or other platforms
Asset use permission in mods/files that earn donation pointsYou are not allowed to earn Donation Points for your mods if they use my assets
Author notes
This author has not provided any additional notes regarding file permissions
File credits
This author has not credited anyone else in this file
Donation Points system
This mod is opted-in to receive Donation Points
Changelogs
Version 1.2.1
- Reduced maximum system RAM consumption during training
- Fixed UI broken after clearing training queue
- Added languages trained on in priors into the voice json
- Stronger VRAM manual management for lower consumption during training
- Added extra error message for missing PRIORS data
- Added better handling of embedding clustering on lower spec systems for big datasets
- Fixed missing dependencies not bundled into compilation from new python environment
- Fixed clustering tool
- Temporarily removed speaker diarization tool
- Fixed regex replace errors
Version 1.2.0
- Added training support for the v3 models
- Added support for whisper models for automatic speech-to-text transcription
- Removed Wav2Vec2 ASR models
- Added automatic audio formatting and audio normalization tools' effects to dataset pre-processing
- Skip audio pre-processing if the files are all already there
- Changed audio normalization tool to also convert stereo to mono
- Removed main screen audio pre-processing button
- Fixed voice exporting
- Fixed end-of-training breaking the UI
- Misc bug fixes
Version 1.1.3
- New tool: Make .srt
- Re-worked dataset voice ID input
- Fixed main app paging, broken after saving a record
- Fixed hidden windows .ini files from breaking some tools
- fixed pyannote hubconf error, via the speaker diarization tool
- Fixed audacity format output for speaker diarization. Adjusted format
- Added error message for when no files of the correct type were given to a tool
- Fixed forcing stage 5 not working, when training
- Misc tweaks/fixes
Version 1.1.2
- Added [Open] button to training panel, to open the checkpoints directory
- Fixed training config defaults being blank before caching
- Added option to AI speaker diarization tool to output Audacity time labels
- Exposed more errors to UI error windows rather than silent errors. More app.log logging details
- Added error window for if there's no corpus data given to similarityTool
- Fixed locale encoding issues with transcript file writing
- Made xVATrainer window remember position in desktop cross-session
- Added [copy to clipboard] button to error modals
Version 1.1.1
- Hotfix for new training errors
- Improved male/female checkpoint config caching
Version 1.1.0
- Added multi-lingual support for the Auto-Transcribe tool
- Changed [male]/[female] fine-tune checkpoint selection to checkboxes
- Fixed WER "Check text quality" colour results persistence in UI
- Fixed cut padding tool not handling files with spaces in their paths (credit: @Pendrokar)
- Added filepicker buttons for folder paths
- Added cross-session caching of user preferences for training configs
- Added caching for graph window viewing size setting
- Fixed cluster tool prefix being numbers only
- Fixed .srt tool not outputting the first split
- Fixed .srt tool not handling files with spaces in their paths
- Changed training numbers to not use scientific notation
- CSS / UI / cmd log visual tweaks
- Misc small bug fixes
Version 1.0.6
- Added .srt split tool
- Stopped spikes prematurely ending training
- Adjusted the target delta values
- Added option to only show the latest configurable few graph points
- Added exception for .ini files in tools
- Fixed wrong path being used as default in export
- Better UI scaling for the training menu
- Fixed occasional endless websocket spinner on app refresh
- Removed milliseconds from log timings
- Fixed record delete button referencing original dataset index, rather than search filtered rows index
- Better reference clearing on training stop for more stable restarting
- Made the graph update with the new delta value as soon as it's logged in the text
- More debug logging around betabinomial tensor mismatch errors
- Misc tweaks, optimizations
Version 1.0.5
- New tool: Cut padding
- Added dataset duplicate detection, searching, and management system
- Added seconds to training log timestamps
- Fixed server.py app version
- Made num workers configurable, for stuck issues
- Added more app.log logging
- Training params tweaks
- Added confirm message to app close, if training
- Fixed dataset viewer rows broken interaction after search
- Fixed not being able to edit voice Id for export
- Made export checkpoints directory accept the root ckpt dir, like in training config
- Pre-filled the export ckpts dir with existing, if the dataset is already in the training queue
- Added caching to export output dir
- Fixed bug where dataset rows sometimes didn't update when changing datasets
- Made Ctrl+S move down to the next line in the dataset rows
- Added hover tooltips to the dataset records' cells
- Made graphs robust to disk polling fails
- Only bring up the config menu when opening training menu from the dataset section if it's not in the queue already
Version 1.0.4
- Fixes for Export inference ffmpeg path
- Lowered max cache size, to lower RAM use during training.
- Improved exporting task order priority
Version 1.0.3
- Added training config toggle for FP16 use
- Made base/websocket servers' ports configurable
- Made the model export accept a choice to do without HiFi-GAN
- Fixed bug in exporting inference
Version 1.0.2
- Hotfix for HiFi-GAN training bug; Other HiFiGAN tweaks
- Better dir watching support, for UI graph refreshing
- More/Better error logging
Version 1.0.1
- Fixed leftover "_16khz" in filenames in transcribe tool
- Fixed global ffmpeg path reference-changed to bundled path
- Fixed some path issues in the training config
- Added specific error message for when no audio files are detected for training FastPitch
- Flushed training graphs to file a bit more often
List of voices available for xVASynth, from both myself and the community: Google doc link You can submit models at the following link: Google forms link
xVATrainer is a companion app for xVASynth, with which you can undertake the entire end-to-end process of preparing speech datasets, and training voice models, ready for use in xVASynth.
Watch the following showcase video for an overview of all the main components of the app:
This is a standalone app, not related to xVASynth. You will of course still need xVASynth for actually using the voice models you create with xVATrainer. To install xVATrainer, extract all the files from the .zip file anywhere (on an SSD would be best for speed), overwrite with any patches, and run the .exe file. Join the Discord for any assistance, with this, or any of the steps in using it, or publishing your creations.
IMPORTANT: The "priors" files NEED to be installed for v3 voice training to be possible. Don't forget to download and install these. This is synthetic data (+ some real data from the NVIDIA HIFI TTS and VCTK datasets) to maintain multi-lingual and voice range capabilities when fine-tuning individual voices, similar to Dreambooth training.
There are three main components to xVATrainer:
Dataset annotation - where you can adjust the text transcripts of existing/finished datasets, or record new data for it over your microphone
Data preparation/pre-processing tools - Used for creating datasets of the correct format, from whatever audio data you may have
Model training - The bit where the models actually train on the datasets
Dataset annotation
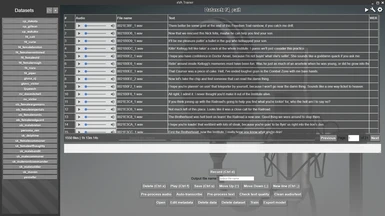
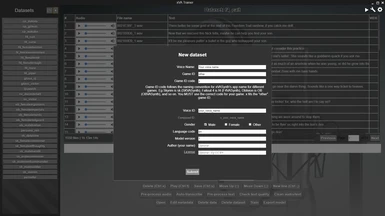
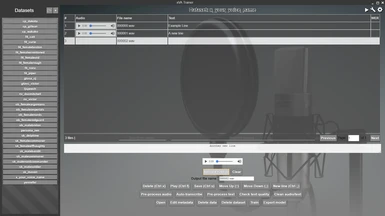
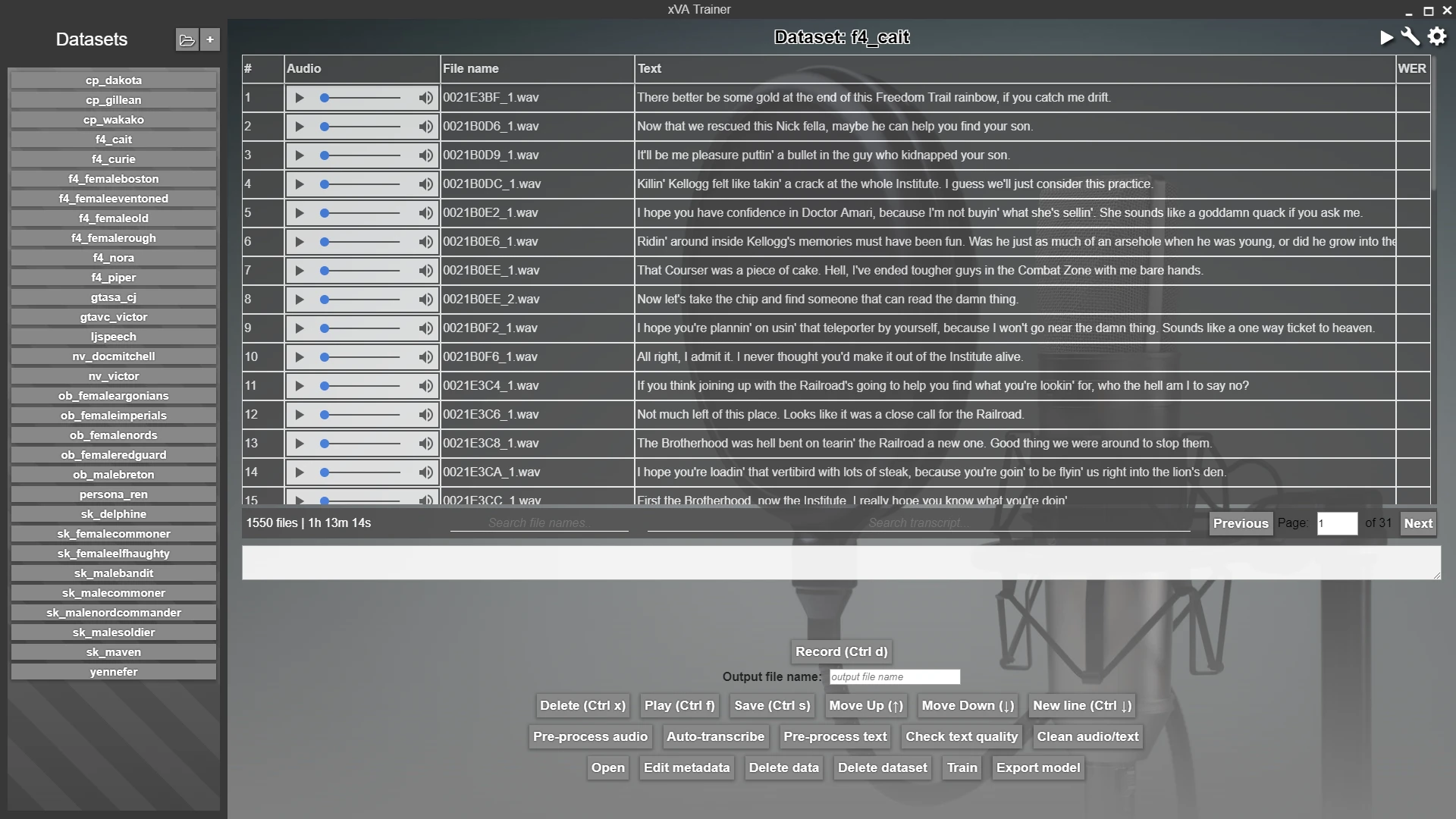
The main screen of xVATrainer contains a dataset explorer, which gives you an easy way to view, analyse, and adjust the data samples in your dataset. It further provides recording capabilities, if you need to record a dataset of your own voice, straight through the app, into the correct format.
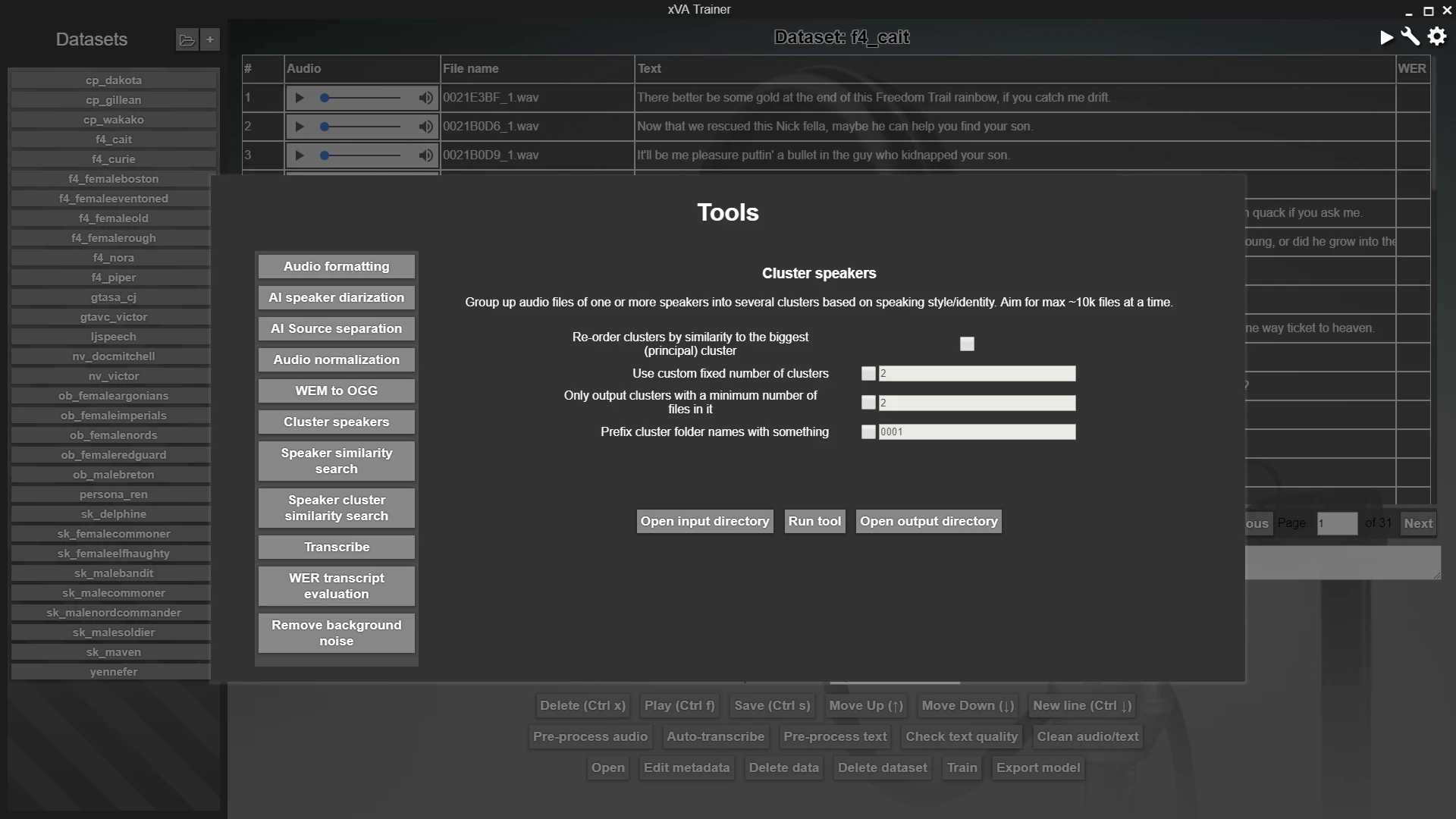
Tools
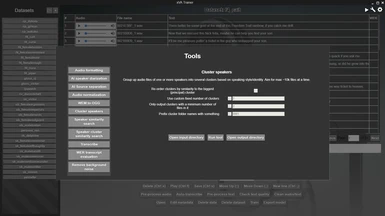
There are several data pre-processing tools included in xVATrainer, to help you with almost any data preparation work you may need to do, to prepare your datasets for training. There is no step-by-step order that they need to be operated in, so long as your datasets end up as 22050Hz mono wav files of clean speech audio, up to about 10 seconds in length, with an associated transcript file with each audio file's transcript. Depending on what sources your data is from, you can pick which tools you need to use, to prepare your dataset to match that format. The included tools are:
Audio formatting - a tool to convert from most audio formats into the required 22050Hz mono .wav format
AI speaker diarization - an AI model that automatically extracts short slices of speech audio from otherwise longer audio samples (including feature length movie sized audio clips). The audio slices are additionally separated automatically into different individual speakers
AI source separation - an AI model that can remove background noise, music, and echo from an audio clip of speech
Audio Normalization - a tool which normalizes (EBU R128) audio to standard loudness
WEM to OGG - a tool to convert from a common audio format found in game files, to a playable .ogg format. Use the "Audio formatting" tool to convert this to the required .wav format
Cluster speakers - a tool which uses an AI model to encode audio files, and then clusters them into a known or unknown number of clusters, either separating multiple speakers, or single-speaker audio styles
Speaker similarity search - a tool which encoders some query files, a larger corpus of audio files, and then re-orders the larger corpus according to each file's similarity to all the query files
Speaker cluster similarity search - the same as the "Speaker similarity search" tool, but using clusters calculated via the "Cluster speakers" tool as data points in the corpus to sort
Transcribe - an AI model which automatically generates a text transcript for audio files
WER transcript evaluation - a tool which examines your dataset's transcript against one auto-generated via the "Transcribe" tool to check for quality. Useful when supplying your own transcript, and checking if there are any transcription errors.
Remove background noise - a more traditional noise removal tool, which uses a clip of just noise as reference to remove from a larger corpus of audio which consistently has matching background noise
Silence Split - A simple tool which splits long audio clips based on configurable silence detection
Cut padding - A tool to remove silence from the start/end of audio clips, with configurable silence detection
.srt split - A tool to split apart long videos (eg films) based on their accompanying .srt subtitle file, into small files with the associated transcript (from the subtitle file)
Make .srt - Automatically generate subtitles for mp4 files, in any of the languages supported by the auto-transcript tool. Useful for sanity checking, and easier external tweaking when using data from a video.
New (v1.2.0)
xVATrainer now has support for non-English languages in the "Transcribe" tool. This is for the automatic transcript generation. The following languages are supported, for both transcription and training:
- ar: Arabic - da: Danish - de: German - el: Greek - en: English - es: Spanish - fi: Finnish - fr: French - ha: Hausa - hi: Hindi - hu: Hungarian - it: Italian - jp: Japanese - ko: Korean - la: Latin - nl: Dutch - pl: Polish - pt: Portuguese - ro: Romanian - ru: Russian - sv: Swedish - sw: Swahili - tr: Turkish - uk: Ukrainian - vi: Vietnamese - wo: Wolof - yo: Yoruba - zh: Chinese (Mandarin)
Languages that will be supported in the "xVASynth v3" models, but which do not currently have ASR models are: Amharic, and Yoruba
Trainer
xVATrainer contains AI model training, for the "v3" models. These are VITS/YTTS models with custom training code, larger capacity, custom text pre-processing pipeline, and custom symbol set. I also refer to them as "xVAPitch" models (the architecture used to have a few more custom tweaks such as explicit pitch conditioning like FastPitch, but then I found a way to do pitch conditioning purely in inference, so I reverted to a simpler design).
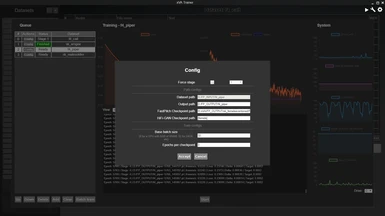
The training follows mainly a single stage of training (Stage 2), but with a quick Stage 1 to warm up the training (training only the text modules on the new text) for maximum transfer learning (fine-tuning) quality. The generated models are exported into the correct format required by xVASynth, ready to use for generating audio with. The auto-stopping criteria is not as clear for these "v3" models. Stage 2 will automatically try to stop at a "maybe good point", but you can optionally then run Stage 3, which is just continuing Stage 2 but without any further auto-stopping. You can also just force stage 3 in the training config. To judge when a good place to stop is, check every 10k or so steps in the checkpoints output directory, which now spits out generated audio files at every checkpoint (and a checkpoint file every configurable x checkpoints). It will use several languages and several speaking styles, so it's up to your preferences to decide when the quality reaches the best quality, before it starts getting worse. Note that the quality sounds better when generated through xVASynth, due to extra post-processing steps.
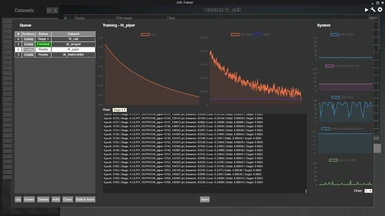
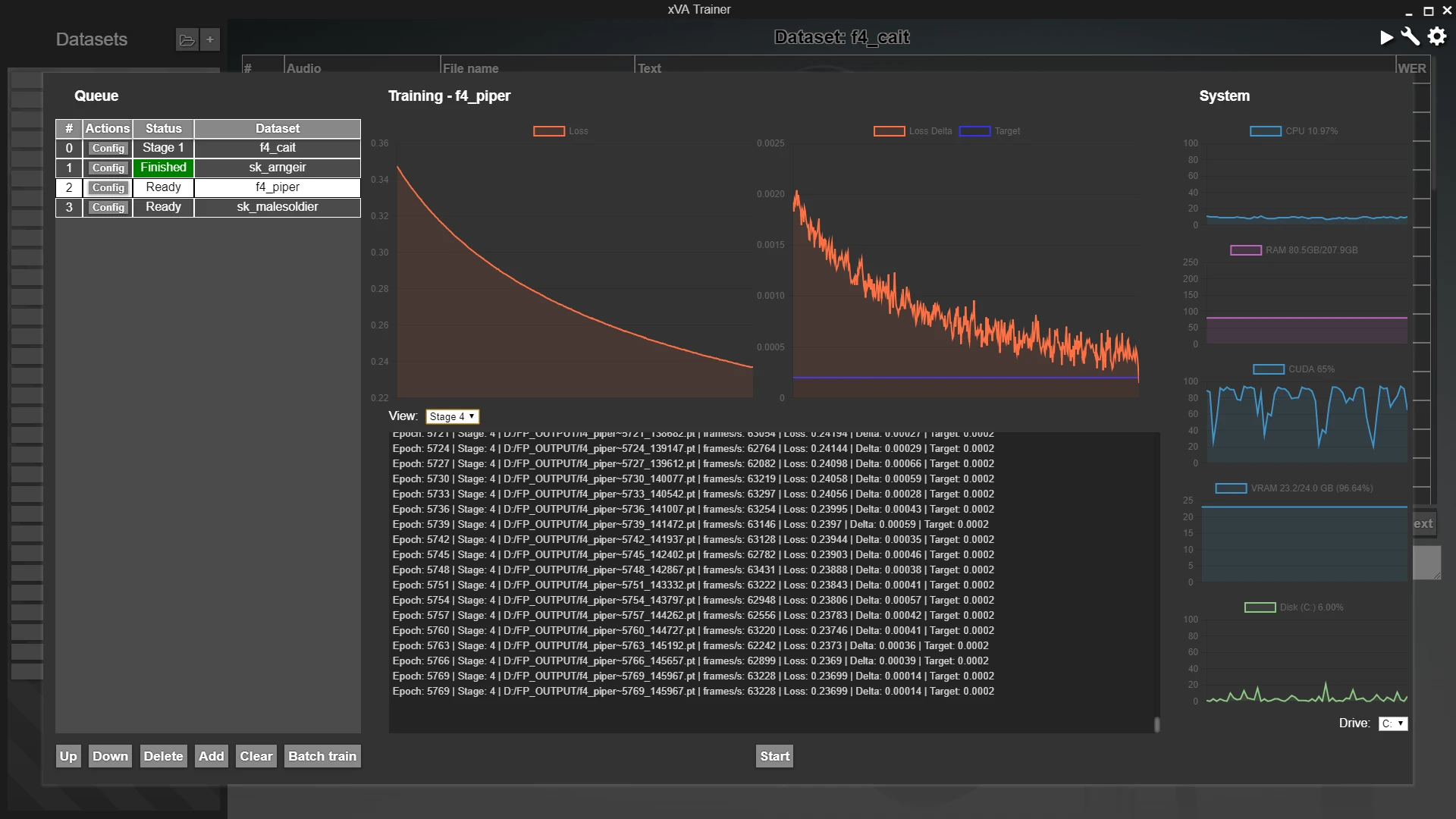
Batch training is also supported, allowing you to queue up any number of datasets to train, with cross-session persistence. The training panel shows a cmd-like textual log of the training progress, a tensorboard-like visual graph for the most relevant metrics, and a task manager-like set of system resources graphs.
You don't need any programming or machine learning experience. The only required input is to start/pause/stop the training sessions, and everything within is automated.
Publishing voices
Once trained, you can do whatever you want with your models, within the limits of the license of the training data (eg, don't go using a model commercially, when the training data cannot be used in the same commercial setting).
If you are adding voices for a game not currently supported in xVASynth, you need to make some accompanying asset files for xVASynth to use. Check the ./resources/app/assets folder in xVASynth to check what these asset files look like. Each game has a background image, and a .json file, both with a base filename of the respective game ID. A new game will need a new game ID. Try to follow the same naming conventions for everything, so that your models/game don't stick out like a sore thumb!
Nexus integration for your game
To add nexus integration for a new game you add, you need to add the nexus game ID number into the .json asset file, in the "nexusGamePageIDs" array. You can check the other files for examples. To get the code(s) (you can add multiple games to your json - eg skyrim le, skyrim se), you can (a) ask me for help, or (b), open xVASynth, press Ctrl+Shift+I, and enter the following into the Console tab: getAllNexusGameIDs("fallout").then(console.log) - where "fallout" is an example search query, and will return a list of all the nexus pages for games with fallout in their title. Expand that list that gets printed into the console, to see all the ID numbers for all the nexus game pages you want to bind to your game/series.
If you post your voice on the nexus (encouraged!), write the file's description (in the Files tab) using the following structure (using Arngeir as an example):
Voice model - Arngeir Model: xVAPitch Voice ID: sk_arngeir
This lets the app parse the voice information in its Nexus menu, enabling people to view and download it from within the app.
FUTURE PLANS: This isn't finished yet, but given that both xVASynth and xVATrainer are available on Steam, something on my TODO list is Steam Workshop integration. Once that is up and running, you will hopefully be able to upload your model(s) to the workshop straight from xVATrainer, and people will be able to download them straight into xVASynth.
Ethical considerations
xVATrainer and xVASynth together function as audio generating/editing software, just as something like Photoshop is for the image domain. In the same style, you need to consider what is/isn't right, to use the software for.
Be considerate of people's wishes, when creating voice models, especially if you're looking to train voice models for aspiring voice actors. Check the license/re-distribution rights for whatever training data you are using. If one is not available, you should check with the owner/voice actor first, and decide on one if you are given permission. This is easier than you'd think. It's mostly just a choice between "CC BY" for no rules, or "CC BY-NC" for non-commercial use. You can check here for more on creative commons licenses, though you can, of course, use whichever license works best. If the data is from a game, it will most likely be non-commercial.
Check Microsoft's take on how to responsibly handle people's voices in artificial synthesis models. They eloquently cover the basics quite well, and you should use this as a good, general starting point, before you start discussing things with your voice actor.
To ensure best practice in fanworks, it is suggested that AI model datapoints should strictly originate from the character performance that the modder is trying to capture (IE, use only lines from the actor portraying that specific character. Do not use samples of their regular speaking voice, etc.). It is also best practice not to include characters from a different franchise in a game they don't already appear in. The latter can cause friction with VAs for several reasons. VAs are concerned with "exposure burn," so every time their voice is identifiably heard in a thing, that kind of contributes to the feeling of their voice being oversaturated and thus less desirable.
It also presents a problem with them feeling like they were contracted to appear as a character in a thing, and when the character is in something else, they feel like they may be mistaken for having supported or endorsed it, etc. So it's best practise to expand performances for characters that exist already in something. It's not a good idea to move that character to another game, or to voice a new character using an AI developed for another character. This isn't to say that doing that is illegal or something, it's just if you want to dodge the VA Ire, that's the best way to go about it.
- These are suggestions based on D0lphin's conversations with NAVA, aiming to better understand modding and leave mods alone. D0lphin had contacted NAVA because a mod in their primary community was taken down, and they wanted to approach NAVA on a professional level to explain the issues surrounding it.
Having said that, the optional downloads section of this app contains models from some community voice actors who have already agreed from people's requests to have their voices trained.
HadToRegister - male
Ellie Mars - female
The following are some voice actors that have NOT given permissions to have their voices trained. DO NOT ask these people for permissions, and DO NOT train their voices. If you ask any voice actors for permissions, and they say no, with no future intentions of saying yes, let me know, and I will add them to this list, in an effort to avoid them being pestered by requests:
Anne Yatco
Cherami Leigh
Kyle McCarley
Ellen Dubin
Jennifer Hale
Wes Johnson
Emma (Vilja)
llamaRCA
Lucien
Laura Post
Felecia Angelle
Elias Toufexis
Xelzaz
CC BY 4.0 Voices
There are a few additional voices uploaded to the misc downloads section trained over non-gaming datasets (NVIDIA HiFi TTS dataset) which are permissively licensed. Do note that although these datasets are licensed as CC BY 4.0, the base v3 model that these are fine-tuned from, was pre-trained on non-permissive data. At the time of writing, there seems to be no clear indication that fine-tuning such a model with permissive data would be a problem, but I am not a lawyer.
Special thanks
Thank you to all the xVASynth supporters, without which, xVASynth and xVATrainer would not have been possible:
D0lphin, flyingvelociraptor, Caden Black, Max Loef, LadyVaudry, Thuggysmurf, radbeetle, TomahawkJackson, Solstice_, Bungles, midori95, eldayualien, John Detwiler, Cecell, Wandering Youth, ellia, Retlaw83, Trixie, CHASE MCKELVY, Leif, ionite, Joshua Jones, Jaktt1337, David Keith vun Kannon, Netherworks (Jo-Jo), neci, Rachel Wiles, Imogen, Deer, Linthar, sadfer, Danielle, Hector Medima, Sh1tMagnet, ReaperStoleMyStyle, AshbeeGaming, TCG, Lady Steel, Mikkel Jensen, CookieGalaxy, GrumpyBen, Adrilz, ReyVenom, dog, bourbonicRecluse, ShiningEdge, Dozen9292, manlethamlet, smokeandash, Elias V, EnculerDeTaMere, SKiLLsSoLoN, J, finalfrog, Hound740, Buck, Yael van Dok, ChrisTheStranger, Isabel, Fuzzy Lonesome, Drake, Beto, AceAvenger, bobbigmac, Alexandra Whitton, yic17, Joebobslim, ThatGuyWithaFace, Sergey Trifonov, Zensho, AgitoRivers, beccatoria, valo999, Ne0nFLaSH, Caro Tuts, Jack in the Hinter, Hammerhead96 ., Bewitched, Para, Wht??? Why??, Shadowtigers, PConD, Lulzar, Ryan W, Wyntilda, Gorim, Krazon, Tako-kun, Walt, Katsuki, Ember2528, RetconReality, Hazel Louise Steele, Laura Almeida, Althecow, PatronGuy, squirecrow, cramonty, crash blue, Syrr, David, Hawkbar, John S., Autumn, pimphat, FeralByrd, Comical, Dogmeat114, Dezmar-Sama, Michael Gill, Jacob Garbe, NerfViking, Dinonugget, RedneckJP007, stormalize, Golem, Luckystroker, Hapax, Vahzah Vulom, Tempuc, CAW CAW, stljeffbb, bart, MrJoy, Zoenna, Calvin, Aosana Bluewing, Dan Brookes, CDante, HunterAP, Kadisra, candied_skull, hairahcaz, nairaiwu, Mar, Paraffine, Nawen_Syaka, Amy Parker, Loseron, katiefraggle, Freon, deepbluefrog, myles.app, hanbonzan, Scientist Salari-Ren, Roman Tinkov, zackc1play, An abstract kind of horror, L, Mihu123, Trisket, Aelarr, Flipdark95, Timo Steiner, humocs, Optimist Vamscenes, Patrick VanDusen, praxis22, Rui Orey, Craig Fedynich, FrenchToast, Dorpz, cesm23, BoB, Cutup, Botty Butler, tjn2222, Matthew Warren, Tom Green, Passionate Lobster, Precipitation, Veks, Baki Balcioglu, Fenris, Patrik K., Oddbrother, E.M.A, DrogerKerchva, Camurai, hthek, iggyzee, Moppy, Stee_Muttlet, asbestos my beloved, TrueBlue, something106, woah00z, Sam Darling, JoshuaJSlone, vvvpppmmm, OvrTheTopMan, munchyfly, DarkNemphis, Justin McGough, Billyro, DIY_Rene, kevmasters, Stu, Sasquatch Bill, Inconsistent, Gothic 3 The Age of War, www48, Slothman, mavrodya petrov, ronaldomoon, Kostin Oleksandr Anatoliiovych, Ryan Lippen, Edward Hyde, Echoes, Vape Gwagwa, Kelg Celcs, Kneelers, Meryl Coker, Alan Gonzalez, PTC001, Hector Medima, CinnaMewRoll, Grant Spielbusch, Sean Lyons, Charles Hufnagel, Kirill Akimov, Mister Lyosea, Anthony Crane, Sh1tMagnet