










0 of 0

About this mod
If you're coming from Mantella, xTTS is an audio generation app similar to xVASynth.
It can consume more VRAM to run xTTS compared to xVASynth.
xTTS use around 2-3 GB of VRAM.
You can run on CPU but it will be slower.
This project is inspired by das
- Requirements
- Permissions and credits
Disclaimer on AI Voice Cloning and Translations:
Before using any custom voices from a mod to generate AI voice lines or train voice models, please ask for explicit permission from the mod author. This applies to creating voice-over translations or any other modifications involving AI-generated dialogue. If permission is not granted, no voices from that mod should be used or cloned.
Base Game Voice Models:
All AI-generated voice models used in this mod are created solely from Skyrim's base game voices. No custom or modded voice assets are used without permission.
For Users and Mod Creators :
Mod Creators : If you notice your custom voice has been mistakenly included or referenced, please contact me, and I will promptly remove it.
Users : If you use any tools related to this mod for voice generation, ensure you have obtained the necessary permissions from the mod authors beforehand.
Thank you for your understanding !
Base Game Voice Models:
All AI-generated voice models used in this mod are created solely from Skyrim's base game voices. No custom or modded voice assets are used without permission.
For Users and Mod Creators :
Mod Creators : If you notice your custom voice has been mistakenly included or referenced, please contact me, and I will promptly remove it.
Users : If you use any tools related to this mod for voice generation, ensure you have obtained the necessary permissions from the mod authors beforehand.
Thank you for your understanding !
xTTS use around 2-3 GB of VRAM.
You can run on CPU but it will be slower.
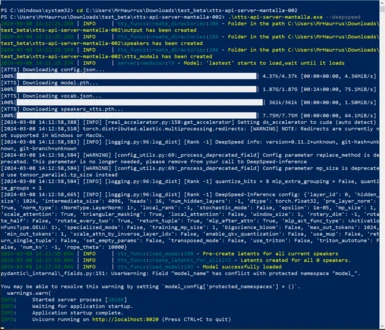
Starting Server :
First extract the content of the archive then :
You can launch the .exe from the windows explorer .
or you can run it from a terminal to have easier debug if it crash (and you can pass argument to it)
xtts-api-server-mantella.exe
will run on default ip and port (localhost:8020)
The initial launch will download the default model.
If there's a problem with the initial download, you can directly download the needed files from: xTTS-V2 (you need to download: config.json, model.pth, speakers_xtts.pth, vocab.json).
This is how your xtts_model folder should look like :
└── xtts_models/
|
└── v2.0.2/
├── config.json
├── model.pth
├── speakers_xtts.pth
└── vocab.json
If you have an NVIDIA GPU that support CUDA run :
xtts-api-server-mantella.exe --deepspeed
It should speed up the generation of audio by 2x-4x the speed.
usage:
xtts-api-server-mantella.exe [-h] [-hs HOST] [-p PORT] [-sf SPEAKER_FOLDER] [-o OUTPUT] [-t TUNNEL_URL] [-ms MODEL_SOURCE] [--listen] [--use-cache] [--lowvram] [--deepspeed] Run XTTSv2 within a FastAPI application
options:
-h, --help show this help message and exit
-hs HOST, --host HOST
-p PORT, --port PORT
-d DEVICE, --device DEVICE `cpu` or `cuda`, you can specify which video card to use, for example, `cuda:0`
-sf SPEAKER_FOLDER, --speaker-folder The folder where you get the samples for tts (default is "speakers")
-o OUTPUT, --output Output folder
-mf MODELS_FOLDERS, --model-folder Folder where models for XTTS will be stored, finetuned models should be stored in this folder
-t TUNNEL_URL, --tunnel URL of tunnel used (e.g: ngrok, localtunnel)
-ms MODEL_SOURCE, --model-source ["api","apiManual","local"]
-v MODEL_VERSION, --version You can download the official model or your own model, official version you can find [here](https://huggingface.co/coqui/XTTS-v2/tree/main) the model version name is the same as the branch name [v2.0.2,v2.0.3, main] etc. Or you can load your model, just put model in models folder
--listen Allows the server to be used outside the local computer, similar to -hs 0.0.0.0
--use-cache Enables caching of results, your results will be saved and if there will be a repeated request, you will get a file instead of generation
--lowvram The mode in which the model will be stored in RAM and when the processing will move to VRAM, the difference in speed is small
--deepspeed allows you to speed up processing by several times, only usable with NVIDIA GPU that support CUDA 11.8+.
Mantella :
In the Mantella config.ini, you can find the following argument that can be passed to the xTTS API server when it is automatically run at the start
of Mantella :
[Paths]
; xtts_server_folder
; The folder you have xTTS downloaded to (the folder that contains xtts-api-server-mantella.exe)
xtts_server_folder = C:\Users\User\Documents\xtts-api-server
[Speech]
; tts_service
; Options: xVASynth, XTTS
tts_service = XTTS
[Speech.Advanced]
; number_words_tts
; Minimum number of words per sentence sent to the TTS
; If you encounter audio artifacts at the end of sentences, try increasing this number.
; Be aware, the higher the number, the longer the TTS audio processing time might take
number_words_tts = 8
; XTTS
; xtts_url
; The URL that your XTTS server is running on
; Examples:
; http://127.0.0.1:8020 when running XTTS locally
; https://{POD_ID}-8020.proxy.runpod.net when running XTTS in a RunPod GPU pod (https://docs.runpod.io/pods/configuration/expose-ports)
xtts_url = http://127.0.0.1:8020
; xtts_default_model
; Official base XTTS-V2 model to use
; Options: v2.0.0, v2.0.1, v2.0.2, v2.0.3, main
; Default: main
xtts_default_model = main
; xtts_device
; Set to cpu or cuda (default is cpu). You can also specify which GPU to use (cuda:0, cuda:1 etc)
; Options: cpu, cuda, cuda:0
xtts_device = cpu
; deepspeed
; Allows you to speed up processing by several times, only usable with NVIDIA GPU that supports CUDA 11.8+.
; Set to 1 to use it or 0 to disable it
; Default: 0
xtts_deepspeed = 0
; lowvram
; The mode in which the model will be stored in RAM and when the processing occurs it will move to VRAM, the difference in speed is small
; If you don't want to pre-generate the latents for every speaker set it to 1 or else it will generate the latents at every start
; Set to 1 to use it or 0 to disable it
; Default: 1
xtts_lowvram = 1
; xtts_data
; Default data for the tts settings of XTTS api server
xtts_data = {
"temperature": 0.75,
"length_penalty": 1.0,
"repetition_penalty": 5.0,
"top_k": 50,
"top_p": 0.85,
"speed": 1,
"enable_text_splitting": true,
"stream_chunk_size": 100
}
Requirement :
In the same manner as xVASynth when used with Mantella, it need the ".lip and .fuz plugin for xVASynth" mod.
Create a /plugins folder at the root of the directory next to "xtts-api-server-mantella.exe", then extract "lip_fuz" and add "FaceFXWrapper.exe"
How to add speakers :
Directory Structure :
- Speakers Folder: By default, this folder is located in the root directory, alongside the "xtts-api-server-mantella.exe" executable. This is where you will store the WAV files that the application uses to synthesize voice outputs. These files should be named after specific voice models, for example, "femaleyoungeager" or "maleslycynical". Additionally, for better organization and potentially more refined results, you can create subfolders within the "speakers" directory named in the same manner as voice models and place multiple WAV samples corresponding to that voice model inside. Each language supported by the app has its corresponding subfolder within the "speakers" folder, following its two-letter code. This setup allows for a more streamlined and organized approach to managing voice samples for different languages.
- Latent Speaker Folder: Parallel to the "speakers" directory, the "latent_speaker_folder" holds generated JSON files that encapsulate the characteristics of the voice samples processed by the server. When the application processes WAV files from the "speakers" directory, it generates these 'latent' JSON files, which contain values representing the aggregate characteristics of all WAVs processed for a specific voice model. This folder also adheres to the language-specific subfolder organization, mirroring the structure of the "speakers" directory. Sharing a single JSON file from this folder can be a more efficient method of distributing a voice model's data, as it negates the need to share multiple large WAV files.
I'm offering a "latent_speaker_folder" right here on this page, already filled with pre-made JSON files for all essential voices. This means you can get Mantella up and running fast, without having to process individual WAV files yourself.
You can download the default latent speaker folder in the following languages : English, French, Italian, German, Spanish, Russian, Polish, and Japanese.
Here is how the "xtts-api-server-mantella/" folder can look like :
xtts-api-server-mantella/
|
├── _internal/
|└── all compiled code from pyinstaller (see github if you want to compile it yourself)
|
├── plugins/
|└── lip_fuz/
|└── all lip & fuz plugin + FaceFXWrapper.exe
|
├── xtts-api-server-mantella.exe
|
|
├── latent_speaker_folder/
|├── en/
||├── femaleyoungeager.json
||└── maleslycynical.json
||
|└── fr/
| ├── femaleyoungeager.json
| └── maleslycynical.json
|
├── speakers/
|├── en/
||├──femaleyoungeager/
|||├── 000a7040_1.wav
|||├── 000d2ae6_1.wav
|||├── 00058fd0_3.wav
|||└── 0002144d_6.wav
||└── maleslycynical/
|| ├── 000e1625_1.wav
|| ├── 000e1628_3.wav
|| ├── 00054f88_1.wav
|| └── 00051978_1.wav
|└── fr/
|├──femaleyoungeager/
|| ├── 000a7040_1.wav
|| ├── 000d2ae6_1.wav
|| ├── 00058fd0_3.wav
|| └── 0002144d_6.wav
|└── maleslycynical/
| ├── 000e1625_1.wav
| ├── 000e1628_3.wav
| ├── 00054f88_1.wav
| └── 00051978_1.wav
└── xtts_models/
├── main/
|├── config.json
|├── model.pth
|├── speakers_xtts.pth
|└── vocab.json
└── femaleyoungeager/
├── config.json
├── model.pth
├── speakers_xtts.pth
├── reference.wav
└── vocab.json
You can load your own model, for this you need to create a folder in models and put your model in it (femaleyoungeager in the following example) :
└── xtts_models/
├── main/
|├── config.json
|├── model.pth
|├── speakers_xtts.pth
|└── vocab.json
└── femaleyoungeager/
├── config.json
├── model.pth
├── speakers_xtts.pth
├── reference.wav
└── vocab.json
There's a video tutorial on this page if you need it !
Link to the Mantella wiki that talk about xTTS, and how to run it in the cloud : Mantella Wiki
Link to my model trainer on github : xtts-trainer-no-ui-auto
Link to github page of the main exe : xtts_api_server_mantella_github
License Compliance NoticeThis mod uses the Coqui xTTS model, which is provided under the Coqui Public Model License (CPML). The following conditions apply to ensure compliance with this license:
- Non-Commercial Use:
- This mod, along with any AI-generated voice models or outputs, is intended strictly for non-commercial purposes.
- Any use of the model or outputs for commercial purposes is strictly prohibited under the CPML.
- Redistribution of Outputs:
- Any redistribution of xTTS-generated outputs (e.g., voice lines, translations) must include a link to the Coqui Public Model License: https://coqui.ai/cpml.txt.
- Redistribution of the model itself is not permitted unless done in accordance with the CPML.
- Acknowledgment:
- The Coqui xTTS model is the intellectual property of its respective licensors and used here in compliance with the license terms.
- For more details, refer to the license here: Coqui Public Model License 1.0.0.
- Mod-Specific Disclaimer:
- This mod does not include or use any custom voices from other mods unless explicit permission has been obtained from the original creators.
- All AI-generated voice lines are created solely from the base game voices provided by Skyrim.