








The encoding is how each character of a text is saved into a file.
Different languages uses different characters: English uses a basic charset (mainly the ASCII one, coded from 1 to 255, that use one byte for each char) while almost all other languages are using an extended charset, to store special char like: éèà 简体中文 語彙 Словарь etc... that require more than one byte per char. There are many encoding standard, and things can easily get hard to manage.
Skyrim used mainly locale charset (coded in Ansi, each language had its own charset) while SkyrimSE uses UTF8 for everything else than english.
This can be interesting to convert a set of string, or a given esp/esm from one encoding to another.
=================================================================
Note: since the beta19 you can change the 'codepage on Load' on the fly with the codepage combolist (7) in the topbar from the main window, once an mod is loaded.

===============================================================
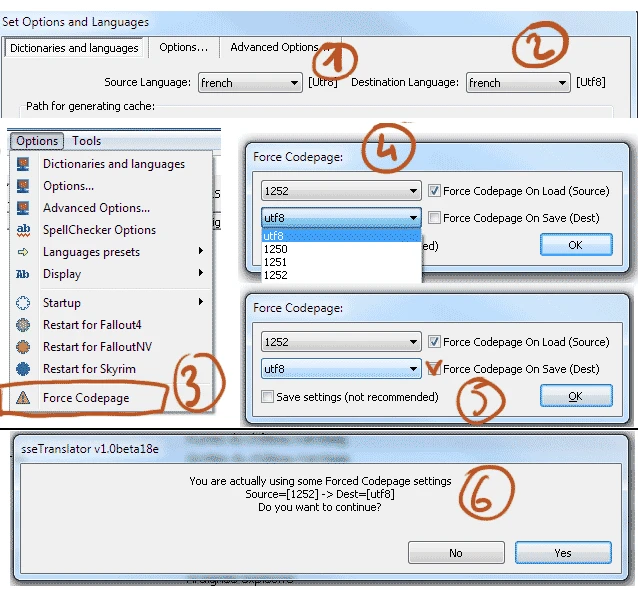
1-2) it's not a mandatory, but it's easier to set your source and dest language as the same, because the tool will not try to autotranslate your mod.
3)to set the output codepage, go to menu -> options ->ForceCodepage
4 - 5)
you get a windows where you can set which codepage to use when you load a mod (esp or strings) and which codepage to use when you export it... choose the codepage then check the belonging checkbox.
Note: if you choose to save settings, the forced codepage will be saved and used even when you restart the tool. This is not recommended, because if you use the tool in the right workspace and languages, the correct codepages are set by default.
Then load a mod.
At this point, take a look on the content of you mod: if you chose the wrong codepage, you will see weird characters. In that case, since beta19 you can adjust the codepage on the fly (7)
When everything looks fine, export (finalize) the mod. You will get a confirmation box (6) for the forced codepage setting, click ok.
Done!
--------------------------
For the reminder here are the codepage used in Skyrim (original)
english=1252
french=1252
polish=1250
czech=1250
danish=1252
finnish=1252
german=1252
greek=1253
italian=1252
japanese=932 or utf8
norwegian=1252
portuguese=1252
spanish=1252
swedish=1252
turkish=1254
russian=1251
chinese=utf8
hungarian=1250
arabic=1256
0 comments