








RegEx is a way to parse string, capture some parts and redispatch or replace them in a new string.
Fallout4translator uses the standard syntaxe for regEx. It's a bit hard to understand at first, but it's really powerful.
There are many tutorial over the internet So I wont explain here the syntax of regex, but how you can use regex in fallout4translator
For the very basics, you can check this: http://regexone.com/ or http://www.zytrax.com/tech/web/regex.htm. (If you know better tutorials, please put them in comments)
To understand the idea, let's take an example: the mod Don't Call Me Settler
It contains a long list of strings like this:
Somerville Place->Oberland Station
Somerville Place->The Slog
County Crossing->Boston Airport
...
each string is separated in 2 parts separated by '->'
1=Somerville Place
2=Oberland Station
Translating this could be a real pain by hand, but using RegEx is an easy way to get those parts and translate them separately automatically.
If you have that mod, open it in fallout4 translator, select a line that uses this format then go to menu ->tool ->RegEx Translation tool
You get a windows:
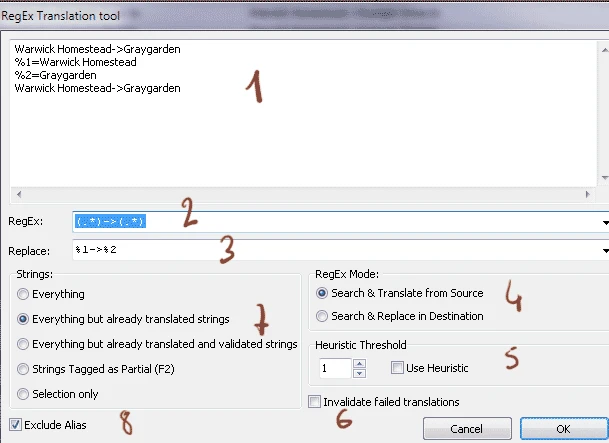
- Shows the selected string and the result of the regex you try to use. You can test the RegEx here.
- There you can enter the regEx itself. If you modify it, the sample in 1 is updated dynamically. Each captured string is stored in direct order 1,2,3...
- There you enter the replace string. By using the reference %1, %2, %3... you call call back the strings captured in 2)
- RegExMode:
-Search and translate: All captured strings are translated if possible then replaced in the format defined in 3)
-Search and replace: change the format and order of given captured parts - Heuristic Threshold: when using search and translated, it's possible to use the heuristic translation. Very low threshold is recommanded . In 0.9.8c+, the heuristic option can be define directly in backreference calls (see below)
- If no translation are found, check here if you want to totally reset the new format (if relevant) or keep it.
- Check here which string you cant to change.
- When checked, strings with <Alias> are ignored
Here is the result after applying the correct regex:
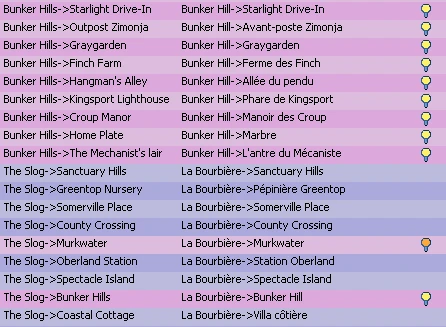
- -Perfect match + direct Translation are in blue
- -Heuristic match are in Pink + yellow light bubble
- -RegEx Match but at least one part wasn't translated are in pink + orange light bubble (if no parts have been translated you can invalidate the string and reset its state by checking 6)
Now, how this works:
To capture a part of a string, you need to use parenthesis blocks.
Lets take a look at the string:
Somerville Place->Oberland Station
Here is how you can parse and split that string in 2 part
Use:
(.*)->(.*)
(.*) means: capture and store in %1 all chars of any type until the '->' which is not captured (no parenthesis) and the second (.*) means: capture and store in %2 all chars left
Result:
%1=County Crossing
%2=Warwick Homestead
By using the translation mode and the replacement string:
%1->%2
Each part will be translated and reformatted
-----
In 0.9.8c+, you can use different syntaxes for calling the backreferences, depending on the effect you want:
#1(Sharp symbol): do not translate the backreference and keep it "as is".
%1((Percent symbol): try to translate the backreference by using strict match (direct translation)
$1(Dollar symbol): try translate the backreference using heuristic match (heuristic threshold can still be adjusted)
ex:
regEx subject: (Note) My Special Demo Note
regEx: ^([\[\(\{\|].+?[\|\]\}\)]) (.+)
Replacement: #1 %2
There, the regEx will not try to translate the part '(Note)' but will try to do a direct translate on the 2nd part 'My Special Demo Note'.
---------
Here are some examples for capture block.
The general logic is always the same: it defines a char type then the iterator (or quantifier) which define how many time the char type is required
(.*): the dot is the char type it means 'all chars type' when then * is the iterator, it means '0 or more times' the given char type
([a-zA-Z]+): [a-zA-Z] is the char type, it means all chars from a to z and A to Z (case sensitive), and '+' is the iterator, it means 1 or more time [a-zA-Z]
([0-9]{3}): looks for a number of exactly 3 digits.
etc...
Take a look at the tutorials I linked above for a deeper understanding.
(to be continued)
0 comments